Durante años, Rayyan ha sido especialmente sólido en el cribado por título/resumen, pero muchos equipos (y, en particular, quienes coordinamos revisiones con volúmenes altos) nos encontrábamos con dificultades claras cuando el proyecto avanzaba hacia el texto completo y la gestión documental.
Las limitaciones de Rayyan
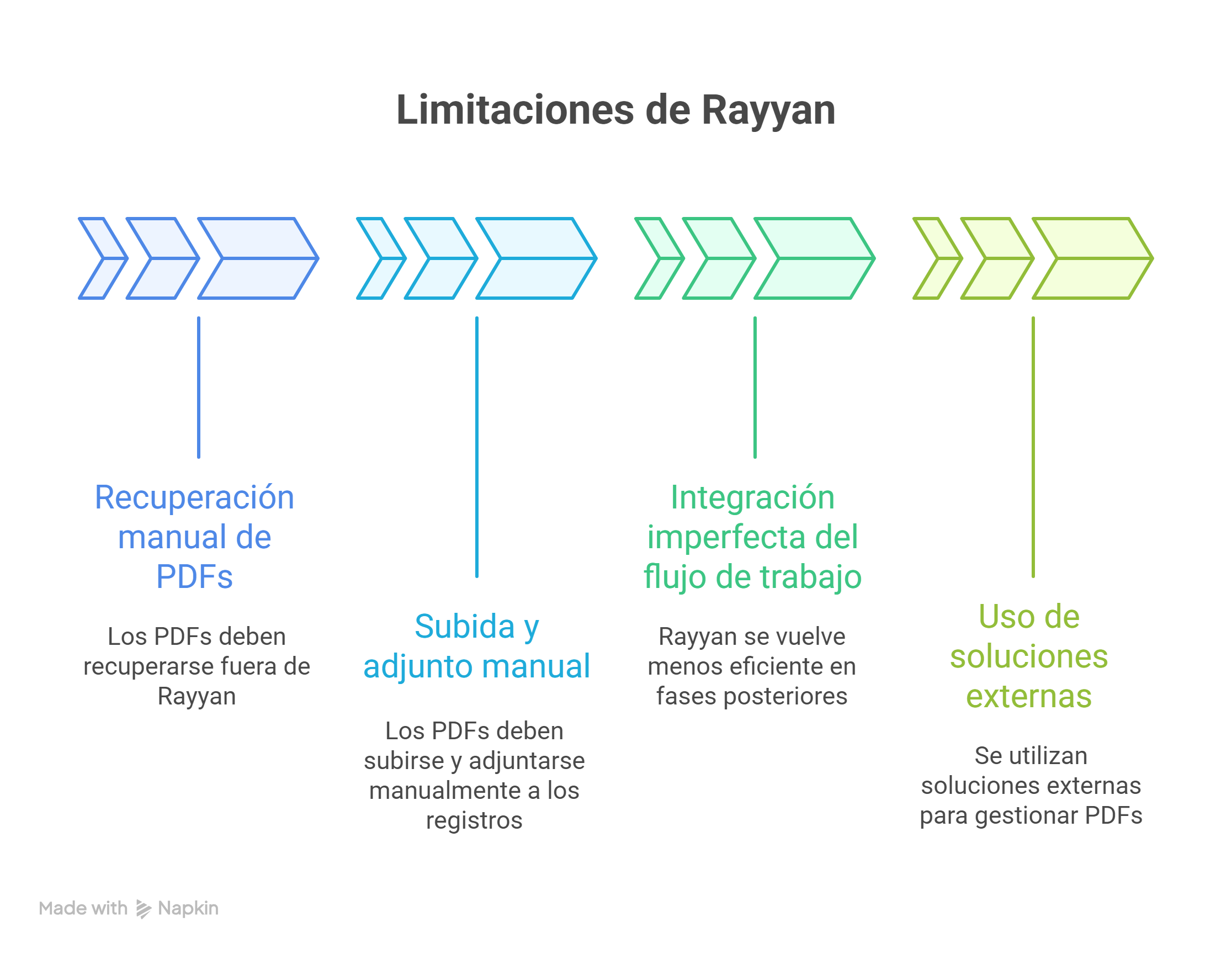
Históricamente, Rayyan se diseñó como herramienta de cribado y, aunque ha ido incorporando módulos posteriores, en la práctica cotidiana se repetían algunos problemas:
Gestión manual de textos completos (PDF): Los PDFs debían recuperarse fuera de Rayyan. Después, había que subirlos y adjuntarlos manualmente a cada registro, uno a uno.
Integración imperfecta del flujo de trabajo: Rayyan resultaba muy eficiente en el primer cribado, pero el proceso tendía a volverse más “pesado” en fases posteriores. Era frecuente recurrir a soluciones externas (carpetas compartidas, gestores bibliográficos paralelos, etc.) para poder trabajar con muchos PDFs de forma operativa.
La novedad: “Mi Biblioteca” (My Library)
Rayyan ha introducido Mi Biblioteca como un espacio estable, reutilizable y conectado a las revisiones, diseñado para centralizar archivos y reducir trabajo manual, especialmente en el cribado a texto completo.
En términos prácticos, “Mi Biblioteca” funciona como una biblioteca personal en la nube dentro de Rayyan, desde la que puedes organizar, conservar y reutilizar materiales (referencias, PDFs y otros archivos) en distintos proyectos.
Beneficios de «My Library»
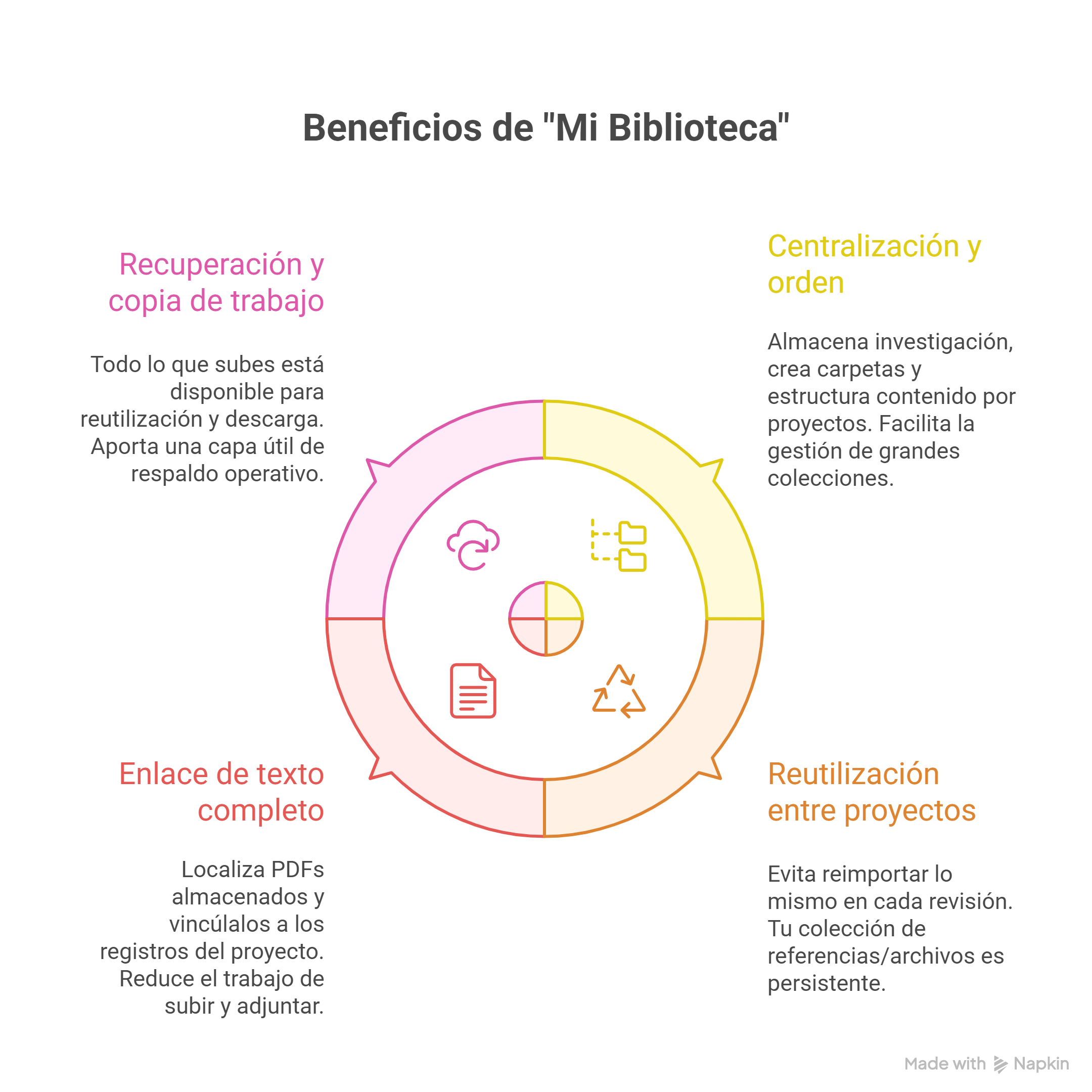
1) Centralización y orden (por fin, “un sitio” para todo)
Permite almacenar una colección propia de investigación, con referencias y textos completos.
Puedes crear carpetas y estructurar el contenido por proyectos, temas o etapas.
Facilita la gestión de colecciones grandes con una lógica de “repositorio” (custodia y reutilización, no solo importación puntual).
2) Reutilización real entre proyectos
Una idea clave es evitar el “déjà vu” de reimportar lo mismo en cada revisión: “Mi Biblioteca” está pensada para que tu colección de referencias/archivos sea persistente y puedas usar los mismos ítems en revisiones diferentes cuando lo necesites.
3) El gran cuello de botella: texto completo (PDF) y su enlace al registro
Aquí está el salto más práctico: durante la fase de cribado a texto completo, puedes localizar PDF ya almacenados en Mi Biblioteca y vincularlos a los registros del proyecto, reduciendo el trabajo de “subir y adjuntar” uno por uno desde cero en cada revisión.
4) Recuperación y “copia de trabajo”
Todo lo que subes queda disponible para su reutilización y descarga, lo que aporta una capa útil de respaldo operativo (especialmente cuando el equipo trabaja con múltiples revisiones o rotación de participantes).
Implicaciones para bibliotecas hospitalarias y equipos de revisión
Reducir trabajo manual repetitivo.
Mejorar la trazabilidad (dónde está cada PDF, cuándo se incorporó, a qué proyecto se vinculó).
Disminuir dependencias de circuitos paralelos (carpetas compartidas + “doble” gestión fuera de la plataforma).
Cautelas (importantes)
No es un sistema de obtención de texto completo: “Mi Biblioteca” no sustituye el acceso: sigue siendo imprescindible disponer de los PDFs por vías legítimas (suscripción institucional, OA, solicitud a autores, etc.).
Qué puedes hacer con cuenta gratuita:
Subir y organizar PDFs y archivos de referencias en Mi Biblioteca, sin límite de espacio tan solo que cada PDF no exceda 100MB, y no subir más de 10 a la vez.
Reutilizar esas referencias en distintas revisiones.
Buscar PDFs en Mi Biblioteca durante el cribado a texto completo y emparejarlos manualmente con las referencias.
Qué queda restringido a planes de pago: El PDF Auto Matching (la asignación automática de PDFs a las referencias) es una funcionalidad solo de pago.
En resumen …
“Mi Biblioteca” supone una notable mejora, ya que actúa en el eslabón más frágil del flujo de trabajo en Rayyan: la gestión del texto completo y su acoplamiento al cribado. Para quienes trabajamos apoyando revisiones sistemáticas desde bibliotecas hospitalarias, este cambio puede traducirse en menos trabajo manual, más orden y más eficiencia en proyectos de alto volumen.
Hasta ahora, diseñar una estrategia de búsqueda sólida, localizar estudios relevantes y manejar cientos de referencias era un trabajo artesanal, intensivo en tiempo y dependiente por completo de la experiencia humana. Sin embargo, la integración de modelos de lenguaje generativo en los procesos de revisión sistemática está modificando de manera sustancial la fase de búsqueda y recuperación de información.
La clave está en entender qué puede hacer cada uno y cómo combinar sus fortalezas para obtener búsquedas más robustas, eficientes y reproducibles en un contexto donde la calidad de la evidencia importa más que nunca.
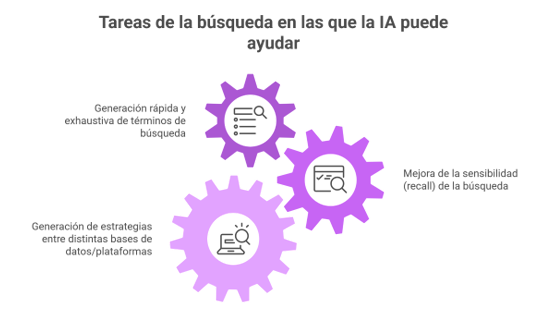
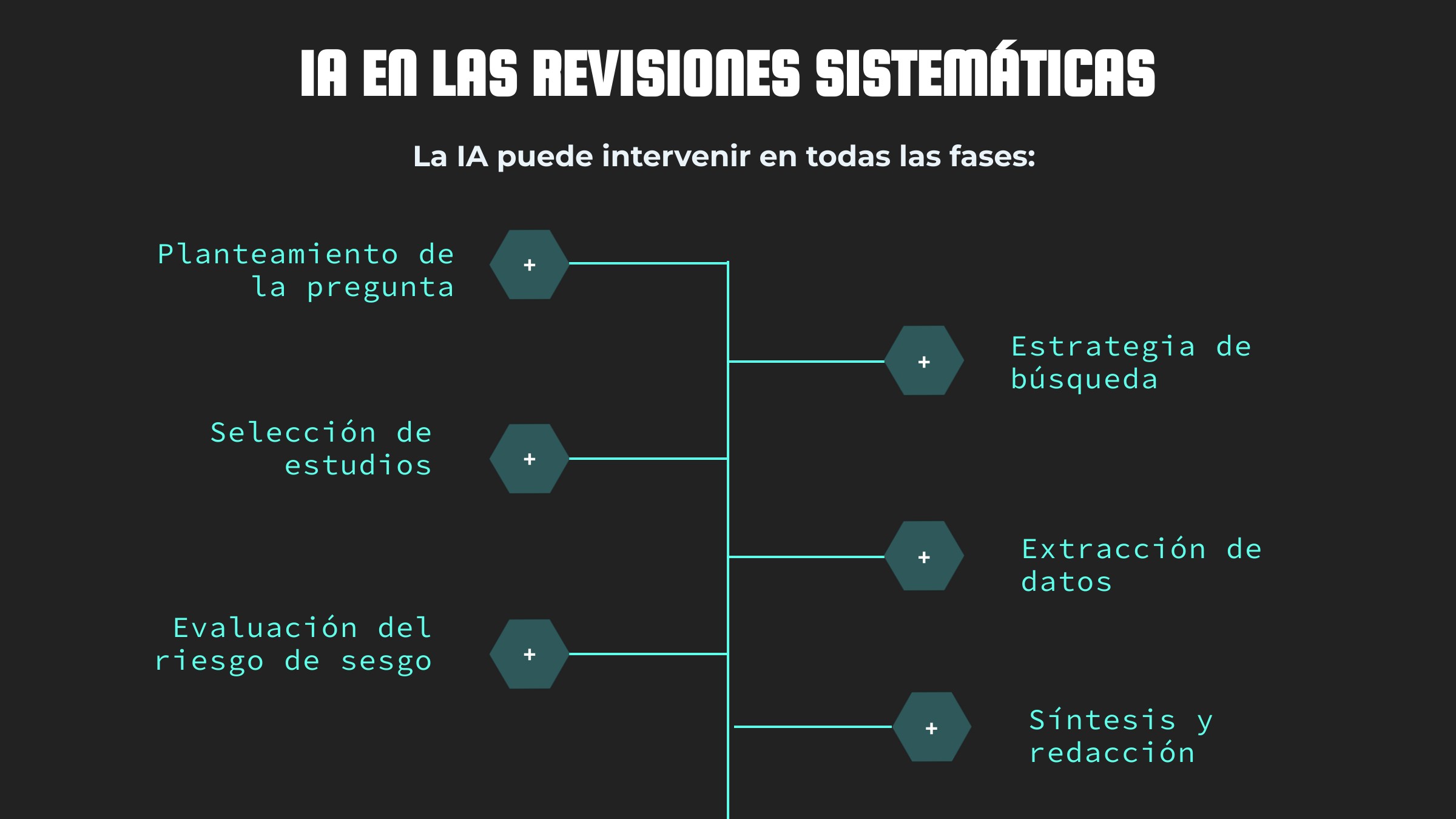
Tareas en las que puede intervenir la IA
La aportación de la IA no reside únicamente en la aceleración de tareas, sino en la capacidad de ampliar, diversificar y estructurar el acceso a la literatura científica, amplificando los procedimientos manuales.
Generación rápida y exhaustiva de términos de búsqueda. Los modelos de IA generativa son capaces de recopilar términos de miles de textos y, a partir de ahí, sugieren sinónimos, acrónimos y variantes de un mismo concepto. En otras palabras, ayudan a descubrir términos relevantes que, de otro modo, podrían pasarse por alto. Esta capacidad resulta especialmente útil en áreas emergentes o interdisciplinarias, donde la terminología aún no está normalizada y la literatura se dispersa en múltiples dominios temáticos.
Aumento de la sensibilidad/exhaustividad (recall) de la búsqueda. Estas herramientas son capaces de producir una primera estrategia de búsqueda con elevada sensibilidad, es decir, muy amplia, recuperando muchísimos resultados. Es verdad que luego hay que limpiarlos y depurarlos, pero esa “primera cosecha” sirve como una base sólida sobre la que seguir afinando la estrategia, añadir filtros y ajustar los términos. En este sentido, la IA funciona como un acelerador: te ayuda a arrancar rápido con un punto de partida fuerte, aunque siempre hace falta la mirada experta del bibliotecario para asegurar que todo tenga sentido y calidad.
Generación de búsquedas booleanas para distintas bases de datos/plataformas. Uno de los avances más visibles es la capacidad de la IA para traducir una estrategia conceptual en consultas operativas adaptadas a la sintaxis de cada proveedor: Ovid MEDLINE, Embase.com, Scopus, Web of Science, CINAHL (EBSCO, Ovid, …), PsycINFO (Proquest, EBSCO, …), entre otros. Esto incluye la aplicación correcta de campos de búsqueda, operadores de proximidad, truncamientos, tesauros controlados y peculiaridades funcionales de cada motor. Esta precisión reduce errores, evita pérdidas de sensibilidad y mejora la reproducibilidad del proceso.
Ventajas/Oportunidades del uso de la IA
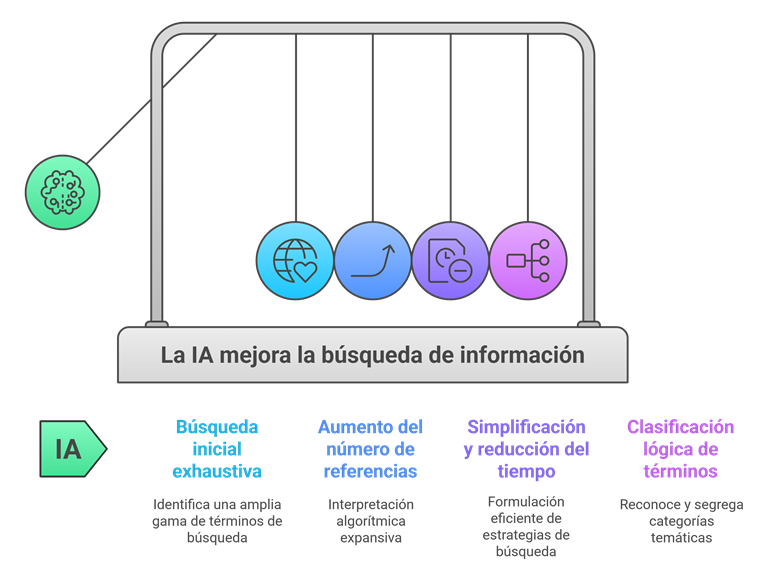
Fase de búsqueda inicial más exhaustiva: La IA puede generar en pocos segundos un abanico enorme de términos, sinónimos y palabras clave relacionadas con un tema. Esto resulta especialmente útil cuando nos enfrentamos a un campo nuevo o del que sabemos poco: la herramienta propone conceptos que quizá no habríamos considerado y evita que la estrategia de búsqueda se quede corta.
Más referencias desde el principio: Las herramientas de IA suelen recuperar mucho más. Su forma de interpretar las palabras clave es más amplia que la nuestra, lo que se traduce en un volumen mayor de resultados. Luego tocará depurarlos, sí, pero arrancar con una red más grande ayuda a no dejar estudios relevantes fuera.
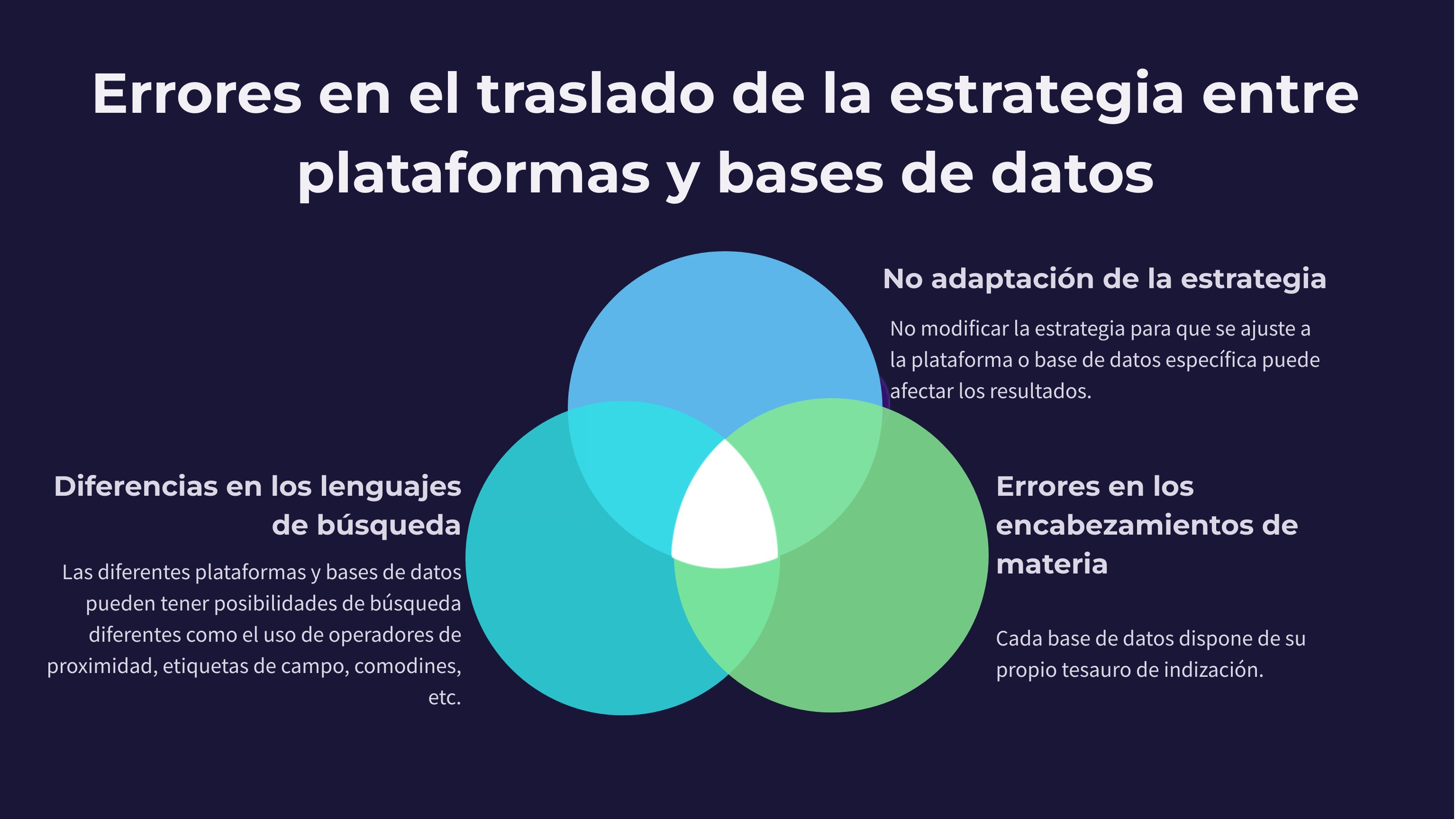
Menos tiempo perdido al adaptar estrategias entre bases de datos: Pasar una estrategia de búsqueda de MEDLINE (PubMed u OVID) a Embase.com, Scopus o WoS es un trabajo pesado, repetitivo y lleno de pequeños detalles que es fácil olvidar. La IA puede hacerlo automáticamente, respetando sintaxis, operadores booleanos y campos correctos en cada plataforma. En la práctica, esto supone menos errores y muchas horas ahorradas.
Orden y lógica en los términos: Además de reunir términos útiles, la IA es capaz de agruparlos por categorías o temas. No solo te dice qué palabras usar, sino que te ayuda a entender cómo se relacionan entre sí, lo que facilita estructurar la búsqueda con sentido.
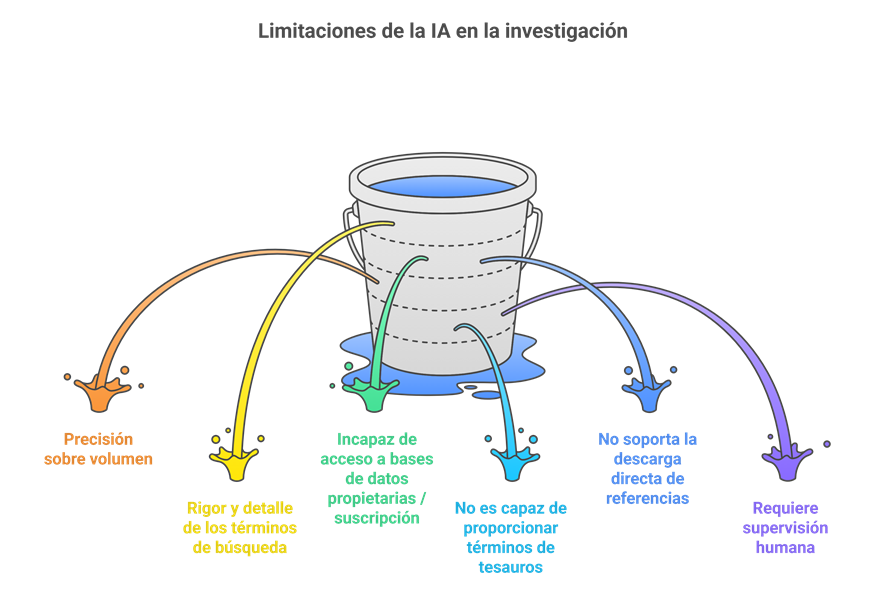
Inconvenientes y retos del uso de IA en las revisiones sistemáticas
Mucho volumen, poca precisión: Que la IA recupere cientos o miles de referencias puede parecer una ventaja, pero tiene trampa: no distingue bien lo relevante de lo accesorio. Esto obliga a dedicar tiempo extra a revisar y descartar estudios que no encajan con la pregunta de investigación. En cambio, una estrategia elaborada por un bibliotecario suele ser más ajustada desde el principio, porque está pensada para responder a criterios concretos y no para abarcar “todo lo que pueda sonar parecido”.
La experiencia humana sigue siendo irremplazable: La IA propone muchos términos, sí, pero no sabe cuándo un matiz importa. Afinar la estrategia de búsqueda, elegir el descriptor correcto o decidir si un término aporta ruido o información útil sigue siendo territorio humano. Las listas generadas por la IA necesitan ser revisadas, depuradas y enriquecidas por alguien que entienda el contexto, las particularidades del tema y las implicaciones metodológicas.
Limitaciones de acceso a bases de datos suscritas: Hoy por hoy, la mayoría de modelos de IA no pueden entrar en bases de datos científicas de pago. Esto significa que no pueden comprobar en tiempo real qué términos están indexados, qué descriptores existen o cómo se estructura un determinado tesauro especializado.
No puede moverse por tesauros especializados: Al no tener acceso a bases como EMBASE, CINAHL o PsycINFO, la IA no es capaz de navegar por sus tesauros y proponer descriptores correctos. Este es un punto crítico porque las estrategias de búsqueda más sólidas combinan términos libres con términos controlados, y esa fineza todavía no está al alcance de las herramientas generativas.
No descarga ni extrae referencias: Otra limitación importante es que la IA no puede descargar los resultados de la búsqueda ni gestionarlos en un gestor bibliográfico. Sigue siendo necesario pasar por las plataformas originales para obtener los registros y preparar la deduplicación o el cribado.
Siempre necesita supervisión: El uso de IA no elimina la figura del bibliotecario experto ni del equipo de revisión. Más bien cambia su papel: deja de ser quien hace cada paso manualmente para convertirse en quien valida, corrige y toma decisiones informadas. Sin esa supervisión, la IA puede generar estrategias amplias, pero no necesariamente adecuadas.
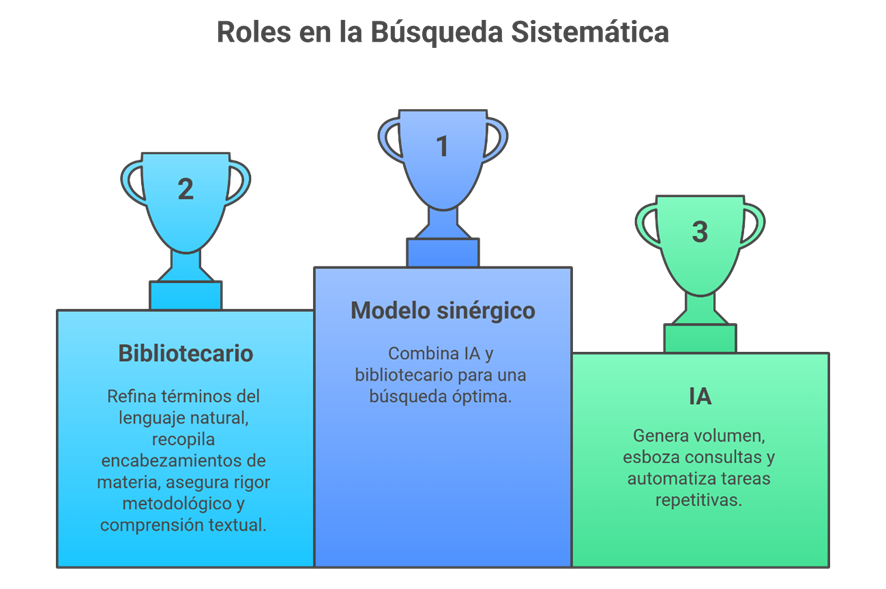
Un modelo sinérgico: IA + bibliotecario
El futuro inmediato no pasa por elegir entre inteligencia artificial o bibliotecario especializado, sino por combinarlos teniendo en cuenta las fortalezas y limitaciones de cada uno de ellos. Cada uno aporta algo diferente y, cuando trabajan juntos, el proceso de búsqueda y revisión gana en velocidad, alcance y rigor.
¿Cuál sería el rol de la IA? La IA es especialmente útil en las primeras fases del trabajo. Su fortaleza está en generar cantidad: propone términos, sugiere combinaciones, construye borradores de estrategias de búsqueda y automatiza tareas tediosas como adaptar consultas entre plataformas o expandir sinónimos. Es rápida y eficiente para mover grandes volúmenes de información.
¿Qué aporta el bibliotecario? El bibliotecario, por su parte, aporta calidad. No solo afina la terminología y valida los conceptos relevantes, sino que es quien domina el uso de tesauros, entiende la lógica de indexación de cada base de datos y detecta inconsistencias que la IA no ve. Además, garantiza el rigor metodológico: sabe cuándo un término es demasiado amplio, cuándo un operador puede distorsionar la pregunta de investigación y cómo documentar correctamente una estrategia reproducible.
La IA debe usarse como compañera de los humanos, no como sustituta.
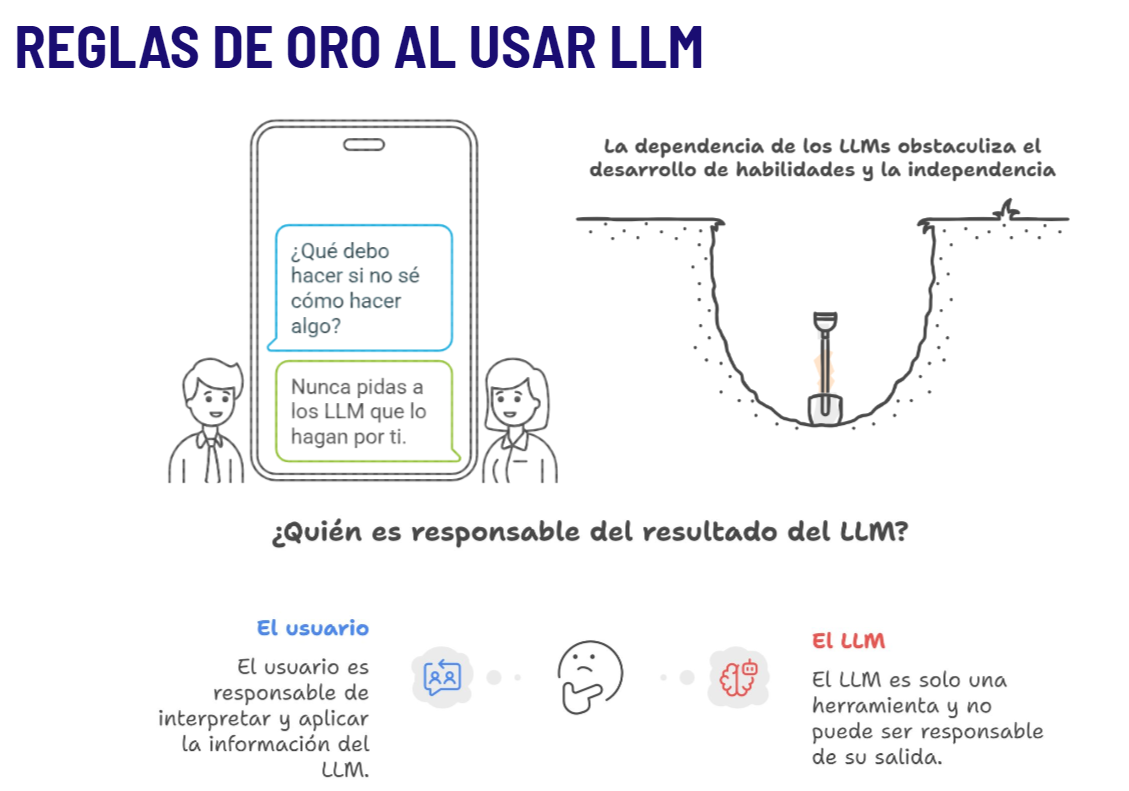
Tú eres, en última instancia, responsable de su síntesis de la evidencia, incluida la decisión de usar IA y de garantizar la adhesión a las normas legales y éticas.
Usa la IA siempre que no comprometas el rigor metodológico ni la integridad de la síntesis.
Debes de informar de forma completa y trasparente del uso de cualquier IA que emita o sugiera juicios.
La inteligencia artificial (IA) puede acelerar y reforzar fases concretas de una revisión sistemática (RS), pero no sustituye el juicio metodológico ni la verificación humana. Esta guía resume cuándo y cómo usarla con seguridad, qué supervisión aplicar y cómo documentar su empleo en protocolos y manuscritos. Esta es una guía práctica y aplicada para equipos de revisión sistemática que desean comenzar a incorporar herramientas de inteligencia artificial (IA) de forma responsable, alineada con la declaración conjunta Cochrane–Campbell–JBI–CEE y las recomendaciones RAISE.
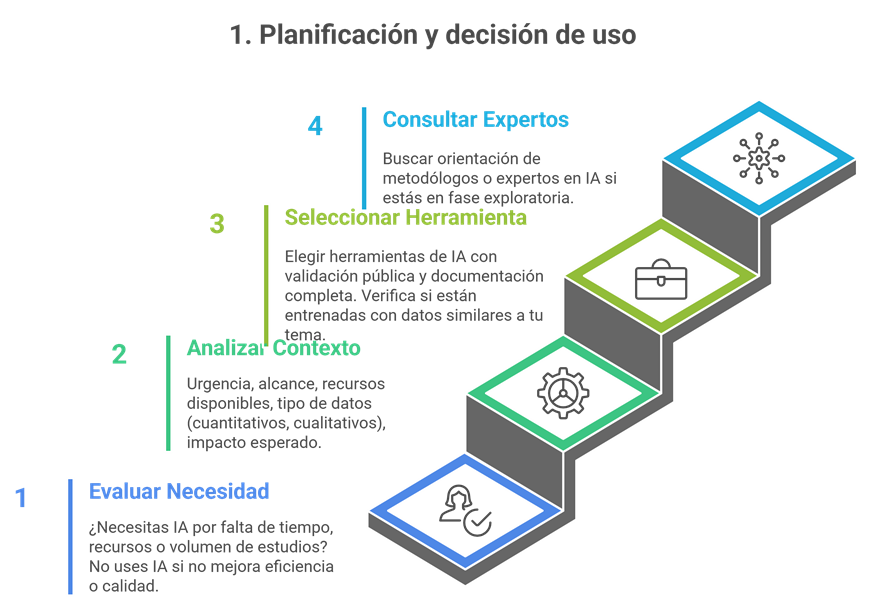
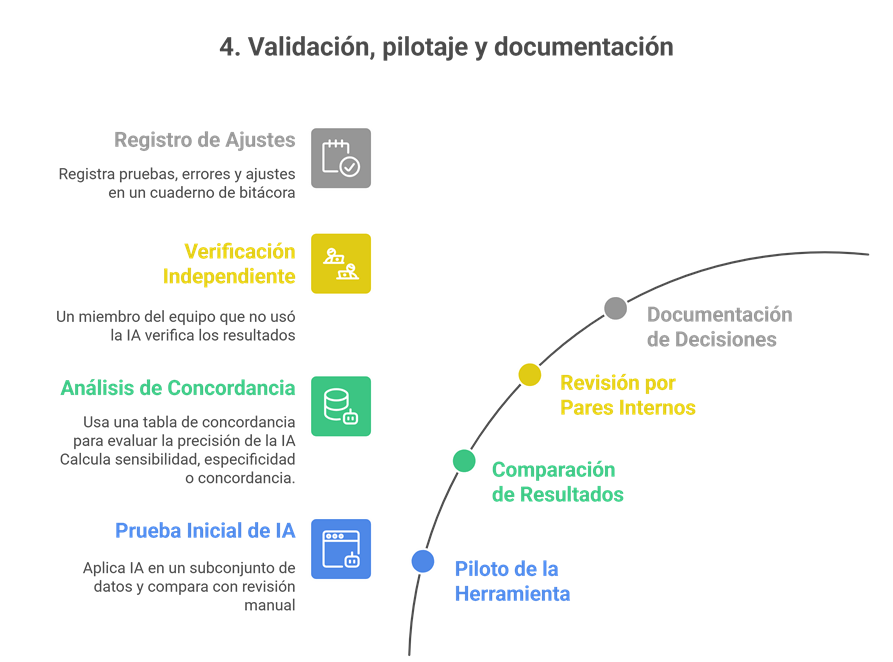
1) Antes de usar IA: 4 decisiones clave
Evalúa la necesidad real. Si la IA no mejora eficiencia o calidad (p. ej., por bajo volumen o buen rendimiento del equipo), no la uses.
Analiza el contexto. Urgencia, alcance, recursos, tipo de datos (cuantitativos/cualitativos) e impacto esperado condicionan la elección de herramientas.
Selecciona con criterio. Prioriza herramientas con validación pública y documentación completa; comprueba si han sido entrenadas en dominios afines a tu tema.
Consulta a metodólogos y expertos si es posible.
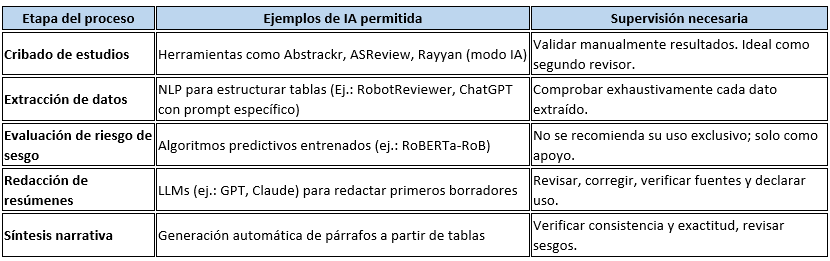
2) ¿Dónde aporta valor la IA? (y qué control aplicar)
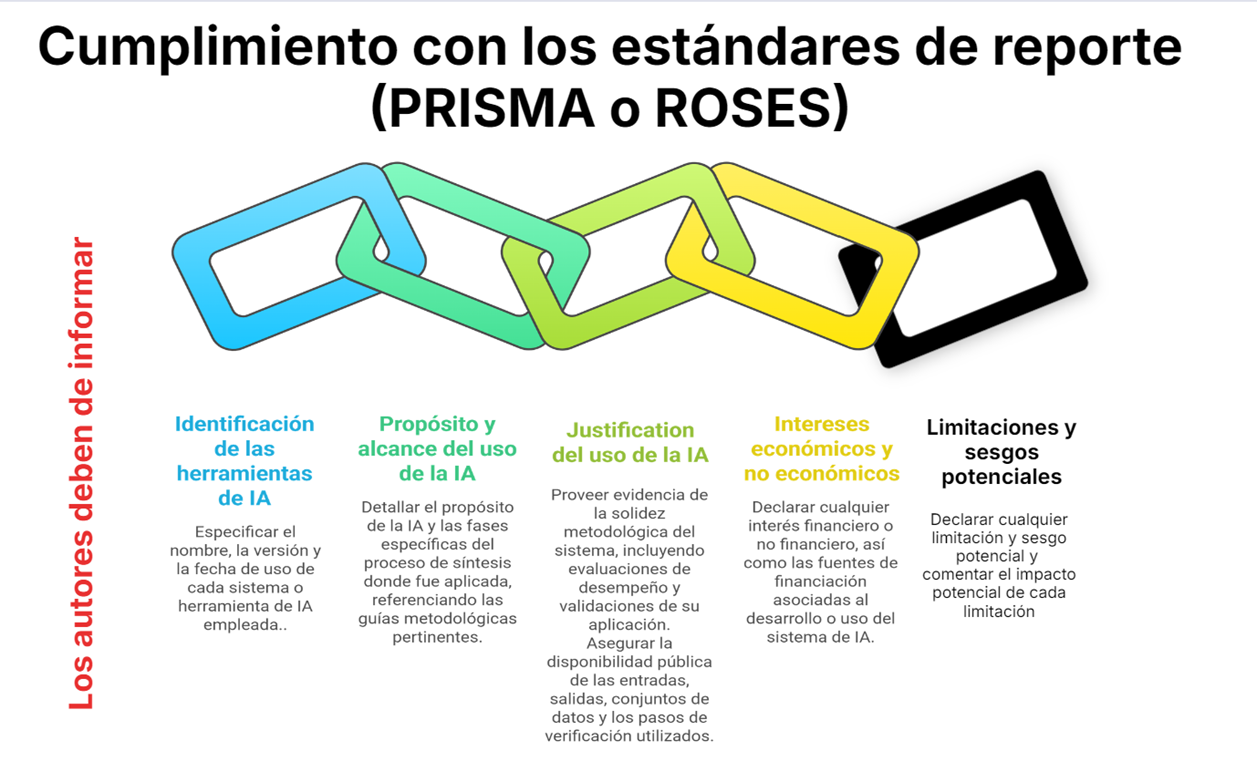
3) Buenas prácticas de reporte
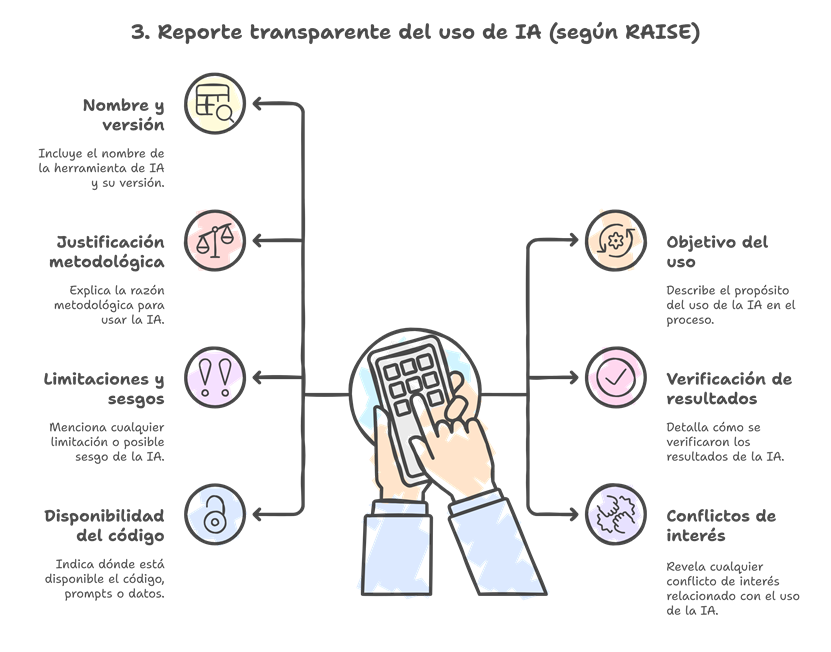
Incluye de forma transparente: herramienta y versión; objetivo de uso (cribado, extracción, redacción…); justificación metodológica (validación/ utilidades); verificación aplicada; limitaciones y posibles sesgos; conflictos de interés; y dónde están código, prompts o I/O (si aplica).
Consejo: Incluye esta información en el apartado Métodos y/o en Material suplementario.
Plantilla genérica de informes que podría usarse adatánda para informar del uso de la IA en RS
We will use [AI system/tool/approach name, version, date] developed by [organization/developer] for [specific purpose(s)] in [the evidence synthesis process]. The [AI system/tool/approach] will [state it will be used according to the user guide, and include reference, and/or briefly describe any customization, training, or parameters to be applied]. Outputs from the [AI system/tool/approach] are justified for use in our synthesis because [describe how you have determined it is methodologically sound and will not undermine the trustworthiness or reliability of the synthesis or its conclusions and how it has been validated or calibrated to ensure that it is appropriate for use in the context of the specific evidence synthesis, if not covered in the user guide, evaluations or elsewhere]. Limitations [of the AI system/ tool/approach] include [describe known limitations, potential biases, and ethical concerns]/[are included as a supplementary material]. [If applicable] A detailed description of the methodology, including parameters and validation procedures, is available in [supplementary materials].
4) Cómo informar el uso de IA en protocolo y manuscrito
5. Formación del equipo
Competencias mínimas recomendadas
Saber interpretar evaluaciones de herramientas de IA
Comprender sesgos algorítmicos (e.g., sesgo de idioma, acceso abierto)
Saber aplicar criterios éticos y legales (protección de datos, plagio)
Capacidad de diseñar prompts precisos y reproducibles si se usan LLMs
La IA optimiza tareas repetitivas y ayuda a estructurar información, pero su fiabilidad depende de una elección informada, pilotaje previo, verificación sistemática y transparencia en el reporte. Si no mejora la eficiencia o la calidad de la RS, no la utilices.
Bibliografía
Flemyng, E., Noel-Storr, A., Macura, B., Gartlehner, G., Thomas, J., Meerpohl, J. J., Jordan, Z., Minx, J., Eisele-Metzger, A., Hamel, C., Jemioło, P., Porritt, K., & Grainger, M. (2025). Position statement on artificial intelligence (AI) use in evidence synthesis across Cochrane, the Campbell Collaboration, JBI and the Collaboration for Environmental Evidence 2025. Environmental Evidence, 14(1), 20, s13750-025-00374–00375. https://doi.org/10.1186/s13750-025-00374-5
Thomas, J., Flemyng, E., Noel-Storr, A., Moy, W., Marshall, I. J., Hajji, R., Jordan, Z., Aromataris, E., Mheissen, S., Clark, A. J., Jemioło, P., Saran, A., Haddaway, N., Kusa, W., Chi, Y., Fletcher, I., Minx, J., McFarlane, E., Kapp, C., … Gartlehner, G. (2025). Responsible AI in Evidence Synthesis (RAISE) 1: Recommendations for practice. https://osf.io/fwaud
Aunque la IA tiene el potencial de transformar los procesos y hacer la síntesis más oportuna, asequible y sostenible, la tecnología es potencialmente disruptiva y conlleva riesgos como la opacidad, el sesgo algorítmico y la creación de contenido fabricado (alucinaciones).
Recientemente se ha desarrollado la guía RISE (Responsible use of AI in evidence SynthEsis) para abordar la necesidad de un consenso sobre qué constituye el uso responsable de los LLMs. Cochrane y JBI han adoptado una posición conjunta y oficial respecto al uso de la Inteligencia Artificial (IA) en la síntesis de evidencia, la cual está formalmente alineada con las recomendaciones RAISE (Responsible use of AI in evidence SynthEsis). Esta postura se estableció en colaboración con la Campbell Collaboration y la Collaboration for Environmental Evidence (CEE), formando un Grupo Conjunto de Métodos de IA (1).
¿Qué son los principios RAISE?
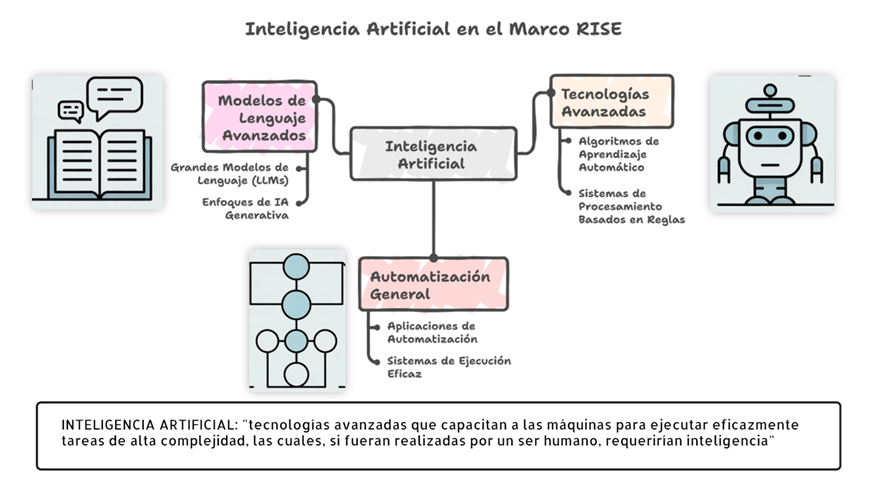
RISE establece un marco de trabajo para garantizar el uso responsable de la inteligencia artificial (IA) y la automatización a lo largo de todo el ecosistema de la síntesis de evidencia. Tiene como objetivo Salvaguardar los principios esenciales de la integridad de la investigación frente a la integración creciente de la IA (2).
Inteligencia artificial dentro del marco RISE
Los autores podrán integrar la inteligencia artificial en sus procesos de síntesis de evidencia y preparación de manuscritos, siempre que se garantice que su uso no comprometerá el rigor metodológico ni la integridad de la evidencia sintetizada. Su implementación debe estar debidamente justificada y sustentada por la solidez metodológica de las herramientas empleadas.
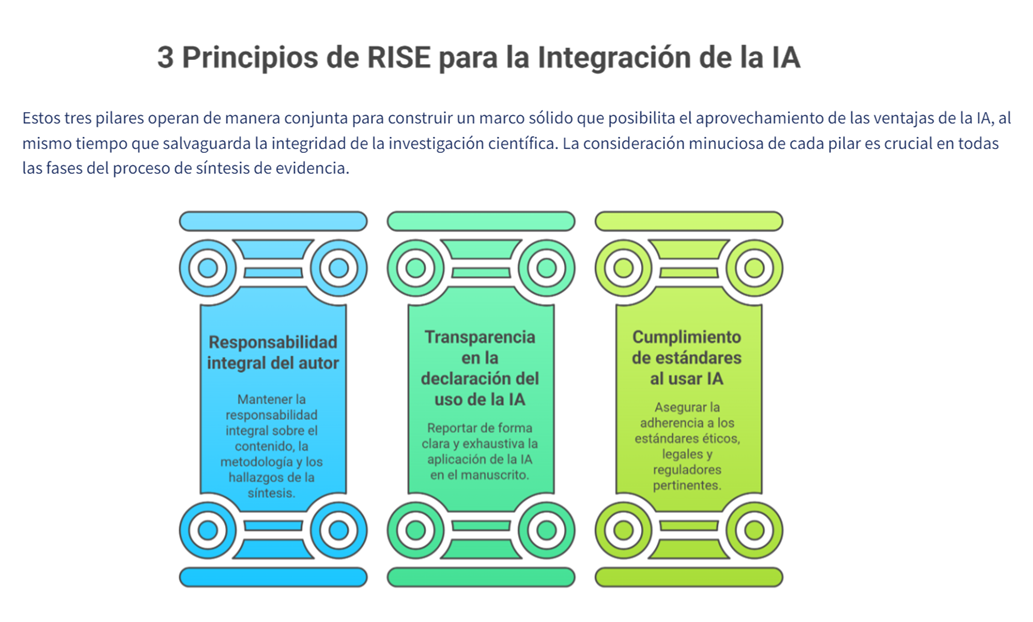
Cómo se implementan las recomendaciones RISE
RISE establece tres categorías principales de recomendaciones para los autores de síntesis de evidencia:
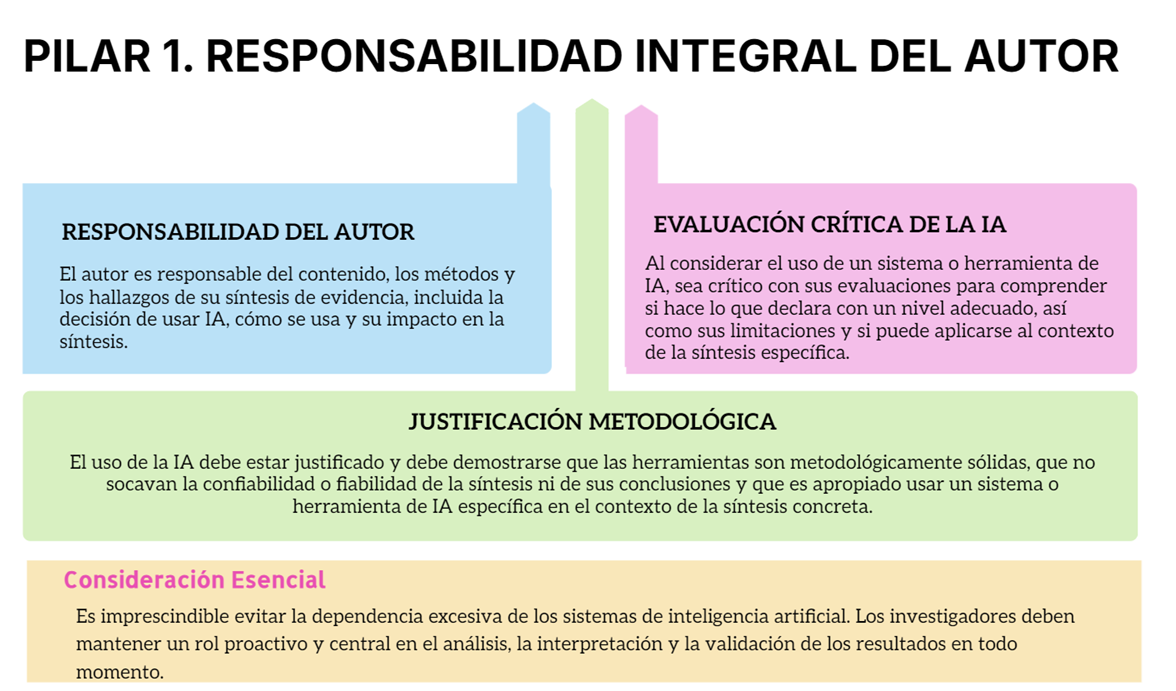
Pilar 1. Responsabilidad última: la firma es tuya.
El autor es el responsable final del contenido, los métodos y los hallazgos de su síntesis, incluyendo la decisión de usar la IA, cómo se emplea y el impacto que tiene en el resultado. El equipo autor responde del contenido, métodos y hallazgos, incluida ladecisión de usar IA, cómo se usa y su impacto. Antes de adoptar herramientas, sé crítico: ¿hacen lo que prometen?, ¿con qué limitaciones?, ¿encajan con tu pregunta y contexto? Justifica el uso: demuestra solidez metodológica y que no compromete la confianza en resultados y conclusiones.
Declara la IA cuando hace o sugiere juicios (elegibilidad, riesgo de sesgo, extracción, síntesis, GRADE, resúmenes). No suele ser necesario declarar correcciones menores de ortografía/gramática, salvo que la revista lo exija.
Incluye siempre:
Nombre(s) del/de los sistema(s) o herramienta(s) de IA, versión(es) y fecha(s) de uso.
Para qué la usaste y en qué fases; guía y cómo se aplicó (incluidas modificaciones).
Justificación y evidenciade desempeño/limitaciones; cómo validaste/pilotaste su uso.
Disponibilidad (si es viable): prompts, salidas, datasets, código; y pasos de verificación.
Intereses (financieros/no financieros) respecto a la herramienta y su financiación.
Limitaciones y sesgos detectados y su posible impacto. Alinea con PRISMA/ROSES y colócalo donde pida la revista (Métodos, Agradecimientos o sección específica).
PILAR 3. Consideraciones éticas y legales.
Cuida plagio, autoría, derechos y licencias, confidencialidad y protección de datos. Si tratas datos sensibles, extrema las garantías.
Plantilla para declarar el uso de IA (copiar/pegar)
Aquí te dejo un ejemplo de modelo de plantilla que puedes utilizar en tu próxima revisión:
Uso de IA y automatización: Durante esta revisión utilizamos [Nombre-herramienta, versión] (acceso el [fecha]) para [fases: búsqueda/cribado/extracción/síntesis/resumen]. Aplicamos [parámetros/modificaciones] y validamos su desempeño mediante [piloto, muestreo, doble ciego, comparación con estándar]. Conservamos prompts, salidas y registros en [repositorio/suplemento]. El equipo no declara [intereses/relaciones] con el proveedor. Limitaciones observadas: [listar]; impacto potencial: [describir]. La decisión final sobre elegibilidad, extracción y conclusiones fue humana.
Tabla traducida al español de RAISE (versión 2.1 en desarrollo a partir del 22 de septiembre de 2025)
Categoría RISE
Más orientación
Mantener la responsabilidad última de la síntesis de evidencia
– El autor es responsable del contenido, los métodos y los hallazgos de su síntesis de evidencia, incluida la decisión de usar IA, cómo se usa y su impacto en la síntesis. – Al considerar el uso de un sistema o herramienta de IA, sea crítico con sus evaluaciones para comprender si hace lo que declara con un nivel adecuado, así como sus limitaciones y si puede aplicarse al contexto de la síntesis específica. – El uso de la IA debe estar justificado y debe demostrarse que las herramientas son metodológicamente sólidas, que no socavan la confiabilidad o fiabilidad de la síntesis ni de sus conclusiones y que es apropiado usar un sistema o herramienta de IA específica en el contexto de la síntesis concreta.
Informar de manera transparente el uso de IA en el manuscrito de la síntesis de evidencia
– Los autores pueden utilizar IA dentro de sus síntesis y para preparar su manuscrito. – Los autores deben declarar cuándo han utilizado IA si esta realiza o sugiere juicios, por ejemplo en relación con la elegibilidad de un estudio, valoraciones (incluida la evaluación del riesgo de sesgo), extracción de datos bibliográficos, numéricos o cualitativos de un estudio o de sus resultados, síntesis de datos de dos o más estudios, valoración de la certeza de la evidencia (incluidos los dominios de GRADE o las calificaciones globales de certeza para un desenlace o hallazgo), redacción de texto que resume la solidez global de la evidencia, las implicaciones para la toma de decisiones o la investigación, o resúmenes en lenguaje sencillo. En general, no es necesario consignar la IA utilizada únicamente para mejorar ortografía, gramática o la estructura del manuscrito, pero recomendamos comprobar la política específica de la revista para asegurar el cumplimiento. – Cumplir con los estándares de notificación establecidos por cada revista, como PRISMA o ROSES. PRISMA, por ejemplo, incluye ítems sobre la notificación de herramientas de automatización usadas en diferentes etapas del proceso de síntesis. Esto debe informarse en la sección especificada por cada revista, como Agradecimientos, Métodos o una sección específica para la divulgación del uso de IA. Si los detalles son extensos o la IA se usa en múltiples etapas, considere materiales suplementarios o una presentación tabular (o ambos). En general, los autores deben informar de lo siguiente: a) Nombre(s) del/de los sistema(s), herramienta(s) o plataforma(s) de IA, versión(es) y fecha(s) de uso. b) El propósito del uso de IA y qué partes del proceso de síntesis de evidencia se vieron afectadas. Citar o referenciar la guía de uso o describir cómo se empleó la IA, incluidas las modificaciones aplicadas. c) La justificación para usar IA, incluida la evidencia de que el sistema o herramienta de IA es metodológicamente sólida y no socavará la confianza o la fiabilidad de la síntesis o de sus conclusiones (p. ej., citando o referenciando evaluaciones de desempeño que detallen el impacto de errores, limitaciones y generalización), y cómo se ha validado (y pilotado, si procede) para asegurar que es apropiada en el contexto de la síntesis específica. Siempre que sea posible y práctico, poner a disposición pública y gratuita las entradas (p. ej., desarrollo de prompts), salidas, conjuntos de datos y código (por ejemplo, en repositorios o como materiales suplementarios) y describir los pasos seguidos para verificar las salidas generadas por IA. d) Cualesquiera intereses financieros y no financieros de los autores de la síntesis respecto del sistema o herramienta de IA, junto con las fuentes de financiación del propio sistema o herramienta de IA. e) Cualesquiera limitaciones del uso de IA en los procesos de la revisión, incluidos sesgos potenciales. Comentar el impacto potencial de cada limitación.
Garantizar el cumplimiento de estándares éticos, legales y normativos al usar IA
Asegúrese de cumplir los estándares éticos, legales y normativos al aplicar IA en su síntesis. Por ejemplo, tenga en cuenta cuestiones relacionadas con plagio, procedencia, derechos de autor, propiedad intelectual, jurisdicción y licencias; y con la confidencialidad, el cumplimiento normativo y las responsabilidades de privacidad, incluidas las leyes de protección de datos.
Conclusión
RAISE no frena la innovación: la encauza. La guía RISE establece un hito esencial en la evolución de la síntesis de evidencia científica. Al definir principios claros para el empleo responsable de la inteligencia artificial, RISE no pretende restringir la innovación, sino orientarla para preservar y robustecer los valores intrínsecos de la investigación rigurosa.
El futuro de la síntesis de evidencia será, ineludiblemente, más automatizado. No obstante, con RISE como pauta, será también más responsable, transparente y fiable. Los investigadores que adopten estos principios no solo utilizarán herramientas poderosas de forma ética, sino que contribuirán a edificar un ecosistema de investigación más sólido y digno de confianza para las generaciones futuras.
Bibliografía
Flemyng E., Noel-Storr A., Macura B., Gartlehner G., Thomas J., Meerpohl JJ., et al. Position statement on artificial intelligence (AI) use in evidence synthesis across Cochrane, the Campbell Collaboration, JBI and the Collaboration for Environmental Evidence 2025. Environ Evid. 2025;14(1):20, s13750-025-00374-5, doi: 10.1186/s13750-025-00374-5.
Thomas J, Flemyng E, Noel-Storr A, Moy W, Marshall IJ, Hajji R, et al. Responsible use of AI in evidence SynthEsis (RAISE) 1: recommendations for practice. In: Open Science Framework, Washington DC: Center for Open Science. https ://doi.org/10.17605/OSF.IO/FWAUD. https://osf.io/.
La inteligencia artificial (IA)—y, en particular, los modelos de lenguaje (LLMs)—ya están ayudando a hacer revisiones sistemáticas (RS) más rápidas y manejables, pero aún no pueden reemplazar el juicio experto ni los métodos sistemáticos consolidados. A continuación resumo qué funciona, qué no, y cómo implantarlo con garantías.
Qué dice la evidencia más reciente sobre LLMs
Una revisión de alcance (n=196 informes; 37 centrados en LLMs) encontró que los LLMs ya se usan en 10 de 13 pasos de la RS (sobre todo búsqueda, selección y extracción). GPT fue el LLM más común. La mitad de los estudios calificó su uso como prometedor, un cuarto neutral y un quinto no prometedor. La búsqueda fue, con diferencia, el paso más cuestionado; en RoB la concordancia con humanos fue solo ligera a aceptable (Lieberum JL, et al. 2024).
¿Dónde aporta más (hoy) la IA?
La IA acelera y prioriza (especialmente en el cribado), pero no sustituye la búsqueda sensible, la evaluación del sesgo ni el juicio experto.
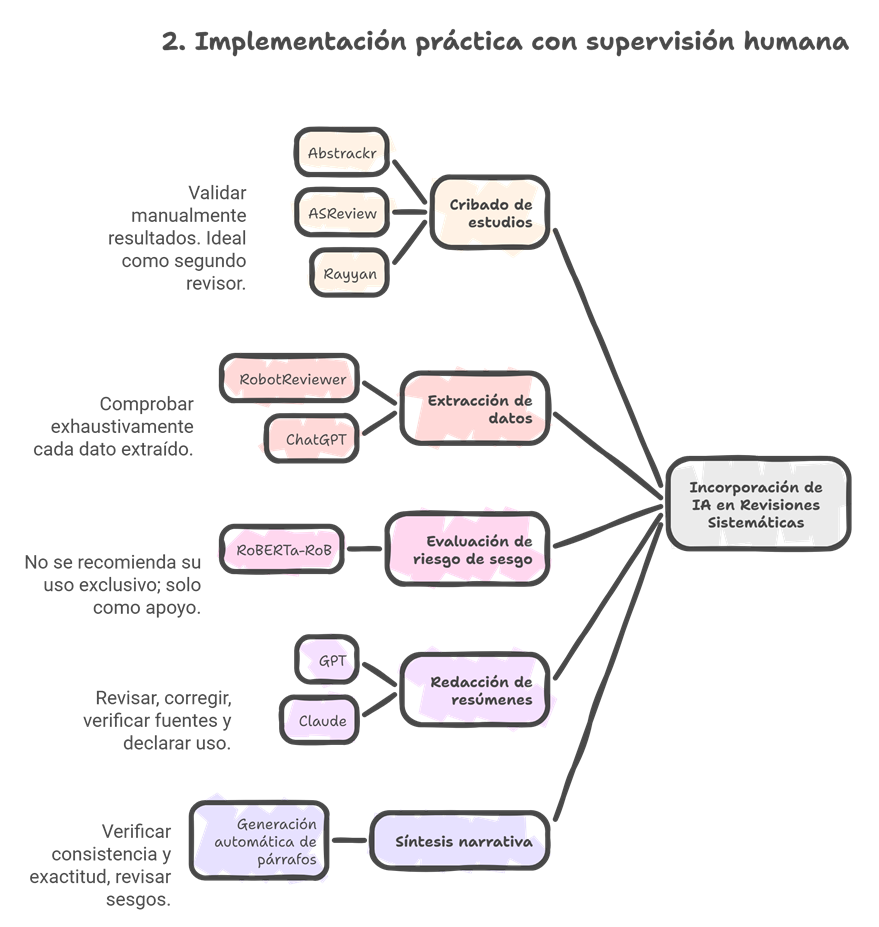
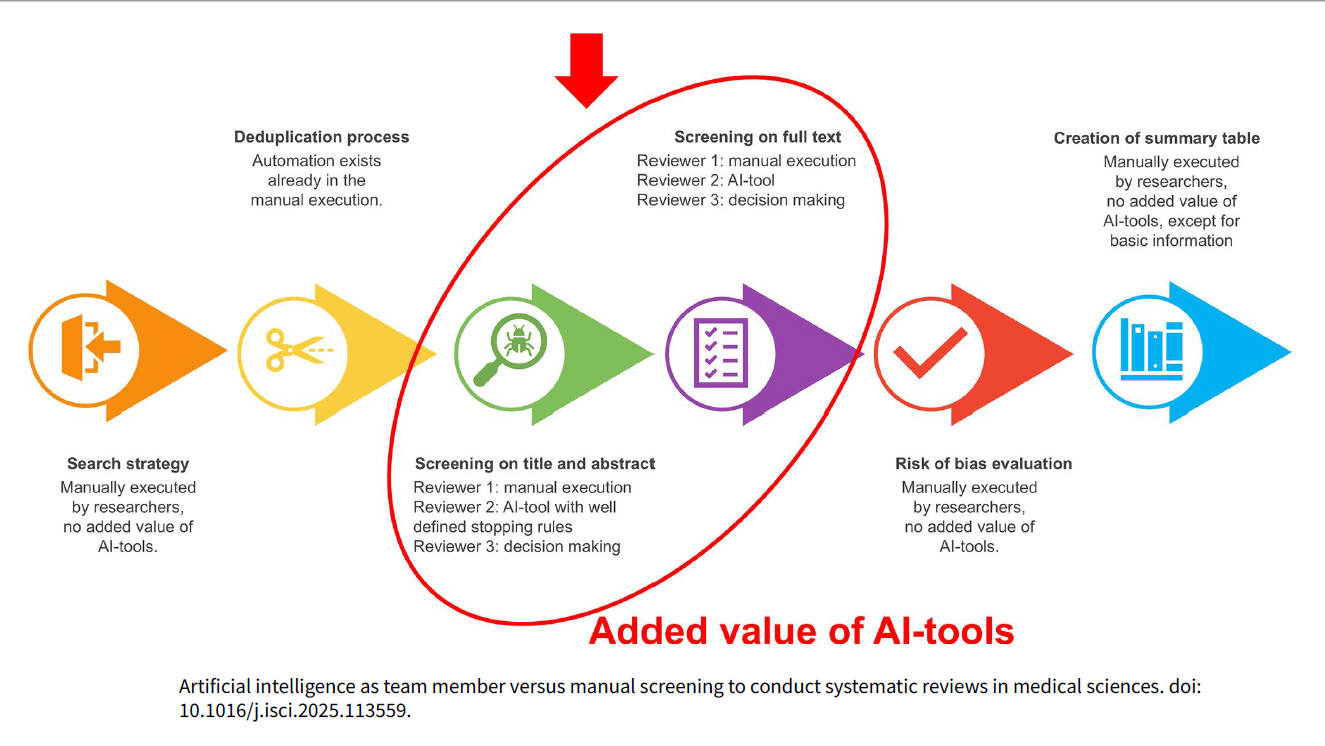
1) Cribado (títulos/resúmenes y, con matices, texto completo)
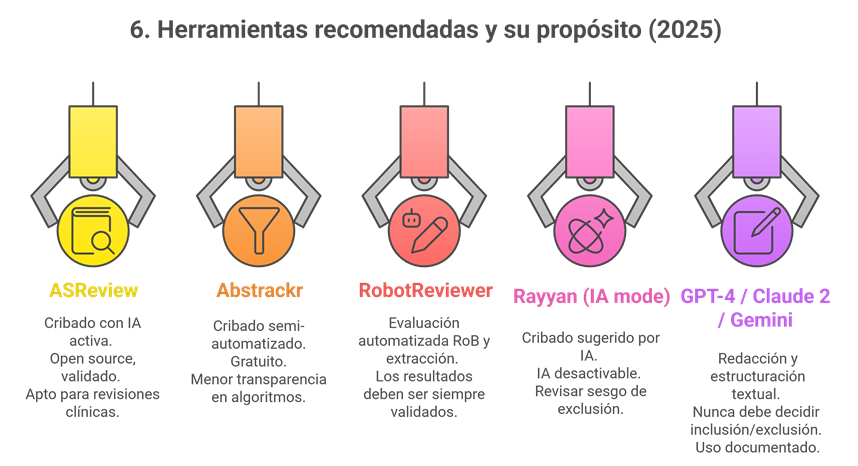
Aprendizaje activo para priorizar lo relevante primero: Ayudar al revisor humano a reordenar los artículos para presentar primero los más relevantes (aprendizaje activo). ASReview y SWIFT ActiveScreener alcanzaron recall altos en títulos/resúmenes (96,48% y 97,89%, respectivamente) y redujeron el number needed to read (NNR). En texto completo, Covidence y SWIFT obtuvieron recall100% con precisión cercana al 50%, útil para priorizar sin suprimir la revisión humana.
Su uso en la primera fase del cribado frente al título/Abstract es prometedor pudiendo reducir la carga de trabajo significativamente, especialmente para el segundo revisor.
Su uso en la fase de escreening frente al texto completo es limitado y todos los artículos deben cribarse para garantizar que no se pierda nada, a pesar de la precisión de la IA
La implicación general es que la IA en esta fase debe verse como una herramienta complementaria y de apoyo, y no como un sustituto completo del juicio y la experiencia humana
2) Extracción de datos (modo asistido)
LLMs y asistentes tipo ChatGPT/Elicit/SciSpace pueden pre-rellenar tablas (autor, año, muestra, intervención…), pero la concordancia varía del 0% al 100% según el campo, y entre herramientas la fiabilidad puede ser baja-moderada; exige verificación por dos extractores humanos.
La extracción de datos es una de las fases del proceso de RS más frecuentemente abordadas por estudios sobre LLMs (Modelos de Lenguaje Grande). La IA puede identificar y extraer información clave, como el diseño del estudio, los resultados, o el tema principal de un artículo, lo que potencialmente minimiza el error humano y reduce el esfuerzo manual3. Dado que la extracción de datos, junto con el cribado, es una de las partes que más tiempo consume en una RS, la capacidad de herramientas como ChatGPT y CoPilot para acelerar esta fase es considerada un beneficio importante. Sin embargo, pesar de los resultados prometedores, la IA aún no está lista para reemplazar la extracción manual y presenta importantes fallas de fiabilidad.
3) Apoyo metodológico y redacción
Buen rendimiento para ideación de la pregunta, PICO, sinónimos y borradores de cadenas booleanas (que un especialista debe validar). En redacción, los LLMs ayudan a esqueletos de métodos/discusión y a preparar síntesis narrativas con control experto.
¿Dónde no conviene delegar (aún)?
A) Búsqueda bibliográfica “end-to-end”: rol de apoyo y supervisión humana
El debate en torno al uso de la Inteligencia Artificial (IA) en la fase de Búsqueda en las Revisiones Sistemáticas se centra en su prometedor potencial para agilizar tareas específicas, contrarrestado por una baja fiabilidad y sensibilidad al intentar reemplazar la metodología de búsqueda tradicional, lo que exige una constante supervisión humana.
Baja Sensibilidad (Recall). Los buscadores IA (p. ej., Consensus, Elicit, SciSpace) mostraron recall muy bajo frente a estrategias manuales multibase: mejor caso ~18% y, en varios escenarios, 0–5%, en parte por cubrir Semantic Scholar y no bases con licencia/tras muro de pago. No sustituyen a MEDLINE/Embase/Scopus/WoS.
Alucinaciones y falta de fiabilidad en las referencias.
Inconsistencia en la Generación de Queries. Incluso cuando se limitan a la tarea de generar queries booleanas para bases de datos (un rol de asistencia), los resultados son impredecibles. Los LLMs no pueden recomendarse para la creación de estrategias de búsqueda complejas.
La IA puede utilizarse para identificar términos clave para el desarrollo de la estrategia y para tareas generales de alcance.
Es crucial que un bibliotecario experto con conocimientos en metodología de revisión valide la estrategia generada por la IA y la edite manualmente, ya que las estrategias generadas por ChatBots podría comprometer los resultados. Se requieren habilidades de prompt engineering para optimizar el rendimiento de la IA en tareas de recuperación de información.
B) Riesgo de sesgo (RoB): esta etapa requiere juicio humano
El debate en torno al Rendimiento de las herramientas de Inteligencia Artificial (IA), como ChatGPT y RobotReviewer, en la etapa de Evaluación de Calidad o Riesgo de Sesgo (RoB) de las Revisiones Sistemáticas (RS), se centra en su pobre fiabilidad inter-evaluador (poor inter-rater reliability) y sus limitaciones metodológicas, lo que las hace actualmente inadecuadas para reemplazar la evaluación humana.
C) Extracción desde tablas/figuras complejas
Los LLMs fallan más cuando los datos están en tablas/figuras o mal estructurados; se necesita lectura experta y herramientas específicas de tablas.
Flujo recomendado: IA-asistida, humano en el bucle
Riesgos (y cómo mitigarlos)
Alucinaciones y referencias falsas → Verificar DOI/PMID y cotejar con texto original.
Reproducibilidad inestable (prompts/temperatura) → Guardar prompts, fijar parámetros, usar corpus cerrado (RAG) cuando sea posible.
Recuerda:
Bibliografía
Kowalczyk P. Can AI Review the Scientific Literaure? Nature. 2024;635:276-8, doi: 10.1038/d41586-024-03676-9.
Lieberum J-L., Töws M., Metzendorf M-I., Heilmeyer F., Siemens W., Haverkamp C., et al. Large language models for conducting systematic reviews: on the rise, but not yet ready for use – a scoping review. 2024, doi: 10.1101/2024.12.19.24319326.
Moens M., Nagels G., Wake N., Goudman L. Artificial intelligence as team member versus manual screening to conduct systematic reviews in medical sciences. iScience. 2025;28(10), doi: 10.1016/j.isci.2025.113559.
Schmidt L., Cree I., Campbell F., WCT EVI MAP group Digital Tools to Support the Systematic Review Process: An Introduction. Evaluation Clinical Practice. 2025;31(3):e70100, doi: 10.1111/jep.70100.
El resumen es, a menudo, la única parte de un artículo que muchos lectores llegan a consultar. Es la primera puerta de entrada para investigadores, clínicos, revisores y facilita la comprensión rápida de los objetivos, métodos y resultados principales de un estudio. Pero además cumple un papel esencial en la recuperación de información: en bases de datos y motores de búsqueda -especialmente si no disponen de tesauro- las búsquedas se realizan fundamentalmente en los campos de título y resumen, y no en el texto completo de los artículos. Esto significa que, si los conceptos clave del estudio no están descritos de forma clara y completa en el resumen, es probable que el artículo no sea recuperado en una búsqueda bibliográfica, aunque sea muy relevante para la pregunta de investigación.
La calidad del resumen no solo es importante para que los lectores comprendan el estudio, sino también para que el artículo sea recuperable y visible en las búsquedas bibliográficas.
En un contexto donde cada vez se publican más artículos, los resúmenes no solo son leídos por personas, sino también procesados por herramientas automáticas de cribado y algoritmos de inteligencia artificial que ayudan en la selección de estudios para revisiones sistemáticas.
Un artículo reciente publicado en el Journal of Clinical Epidemiology (Write Your Abstracts Carefully – The Impact of Abstract Reporting Quality on Findability by Semi-Automated Title-Abstract Screening Tools, Spiero et al., 2025) demuestra con claridad esta idea:
Resúmenes de mayor calidad (medidos con los criterios TRIPOD) son más fáciles de identificar como relevantes por herramientas de cribado semiautomatizado.
El uso de subapartados en resúmenes estructurados también aumenta la probabilidad de que los artículos sean detectados.
En cambio, aspectos como la longitud del resumen o la variación terminológica no influyen en la capacidad de las herramientas para identificar artículos relevantes.
¿Por qué es importante esto?
Porque si los resúmenes están mal redactados, los estudios relevantes pueden pasar desapercibidos, lo que introduce sesgo de selección en las revisiones sistemáticas, y debilita la calidad de la síntesis de la evidencia.
Implicaciones prácticas
Para los autores de los artículos:
Redactar resúmenes completos, claros y estructurados, siguiendo las guías de reporte, aumenta la visibilidad de sus estudios en revisiones sistemáticas.
Una mala calidad de resumen puede traducirse en menor probabilidad de ser incluido en síntesis de evidencia, incluso si el estudio es relevante.
Para los equipos de revisiones sistemáticas:
Deben ser conscientes de que los algoritmos de cribado dependen de la calidad del resumen: resúmenes pobres pueden ser omitidos por las herramientas.
Es recomendable mantener estrategias de búsqueda amplias y sensibles, y vigilar el posible sesgo por omisión de estudios relevantes con resúmenes deficientes.
Documentar esta limitación metodológica en los protocolos y discusiones de las revisiones.
Para los bibliotecarios:
Al apoyar en búsquedas y cribado, conviene alertar sobre el riesgo de sesgo asociado a resúmenes mal redactados.
Los bibliotecarios pueden desempeñar un papel formativo, promoviendo la adhesión a guías de reporte (CONSORT, STROBE, TRIPOD…) entre investigadores y clínicos.
En la práctica, esto refuerza el papel del bibliotecario como garante de la calidad metodológica y transparencia en la síntesis de la evidencia.
En definitiva, escribir un buen resumen no es solo un ejercicio de comunicación científica: es una garantía de visibilidad, accesibilidad y rigor científico.
Referencia
Spiero I, Leeuwenberg AM, Moons KGM, Hooft L, Damen JAA, Write Your Abstracts Carefully – The Impact of Abstract Reporting Quality on Findability by Semi-Automated Title-Abstract Screening Tools. J Clin Epidemiol. 2025, doi: https://doi.org/10.1016/j.jclinepi.2025.111987.
La inteligencia artificial está irrumpiendo con fuerza en la síntesis de evidencia. Un estudio reciente de la Agencia Canadiense de Medicamentos (CDA-AMC) ofrece datos interesantes que conviene conocer (Featherstone R, Walter M, MacDougall D, Morenz E, Bailey S, Butcher R, et al. Artificial Intelligence Search Tools for Evidence Synthesis: Comparative Analysis and Implementation Recommendations. Cochrane Evidence Synthesis and Methods. 2025;3(5):e70045, doi: 10.1002/cesm.70045.).
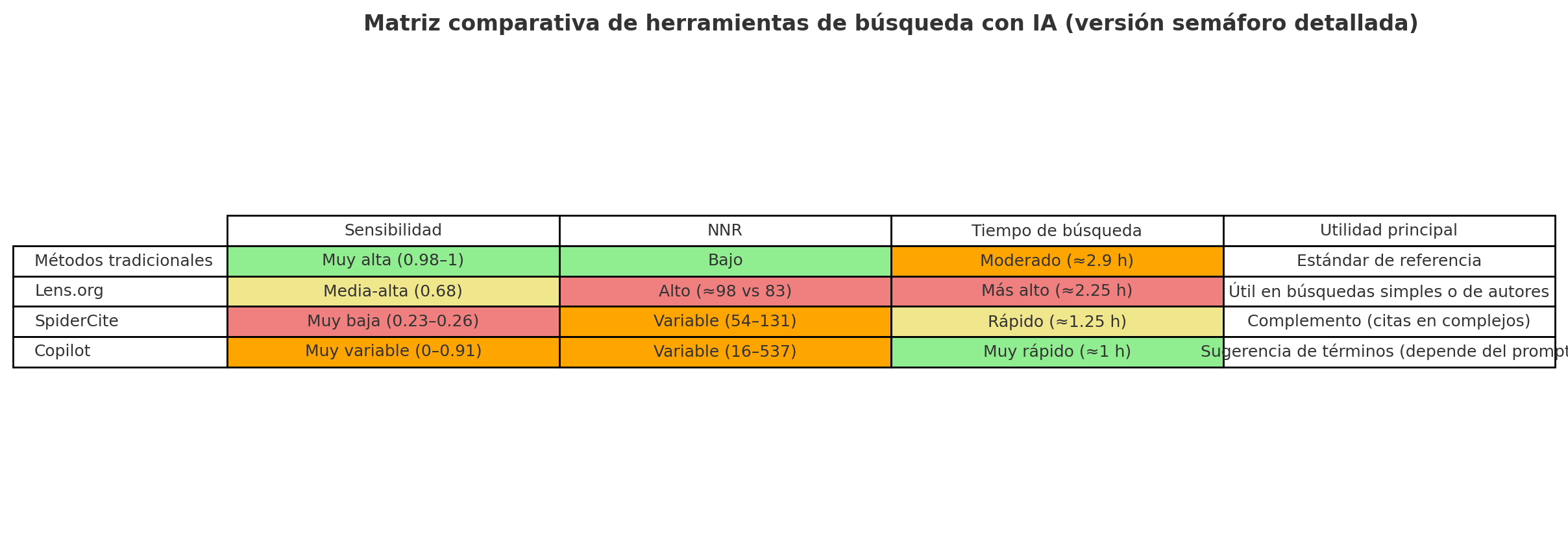
Este artículo tuvo como objetivo evaluar el potencial de herramientas de búsqueda basadas en inteligencia artificial (Lens.org, SpiderCite y Microsoft Copilot) para apoyar la síntesis de evidencia vs. métodos de búsqueda tradicionales y establecer recomendaciones de implementación bajo un enfoque “fit for purpose”, es decir, utilizar cada herramienta solo para tareas específicas donde aporten valor. Se evaluaron siete proyectos completados en la agencia, aplicando búsquedas de referencia (método tradicional) frente a búsquedas con cada herramienta de IA. Se midieron sensibilidad/recall, número necesario a leer (NNR), tiempo de búsqueda y cribado, y contribuciones únicas de cada herramienta. Además, se recogió experiencias de los especialistas en información sobre usabilidad, limitaciones y sorpresas en el uso de los tres sistemas.
Resultados
Método / Herramienta
Sensibilidad promedio
Diferencias entre proyectos simples y complejos
NNR (número necesario a leer)
Tiempo de búsqueda
Observaciones principales
Métodos tradicionales
0.98 – 1 (casi perfecta)
Consistentemente alta en todos los proyectos
Más bajo que IA
2.88 h en promedio
Estándar de referencia, máxima fiabilidad
Lens.org
0.676
Simples: 0.816 Complejos: 0.6
Más alto que el estándar (98 vs 83)
Mayor tiempo (2.25 h, más que Copilot o SpiderCite)
Mejor de las IA, pero menos eficiente; útil en búsquedas simples y de autores
SpiderCite
0.23 – 0.26
Similar en simples y complejos
Variable (Cited by mejor que Citing)
~1.25 h
Muy baja sensibilidad, pero puede aportar referencias únicas en temas complejos; solo útil como complemento
Copilot
0.24 (muy variable: 0–0.91 según proyecto)
Simples: 0.41 Complejos: 0.15
Muy variable (mejor en simples, muy alto en complejos)
Más rápido (0.96 h promedio)
Dependiente de la calidad de los prompts; no sustituye estrategias, útil para sugerir palabras clave
Sensibilidad = proporción de estudios relevantes efectivamente recuperados. NNR = número necesario a leer; cuanto menor, mejor eficiencia de cribado.
Verde = mejor desempeño relativo. Amarillo = intermedio / aceptable. Rojo = débil. Naranja = muy variable según proyecto.
Discusión
Las herramientas de IA mostraron rendimiento variable e inconsistente, lo que implica que no pueden reemplazar las búsquedas profesionales estándar en revisiones sistemáticas.
Pueden generar falsa confianza en usuarios sin experiencia. Se requiere conocimiento experto en construcción de estrategias y en validación de resultados para corregir limitaciones.
Limitaciones del estudio: solo se evaluaron 7 proyectos y 3 herramientas, sin analizar combinaciones entre ellas
Recomendaciones de implementación
La CDA-AMC propuso un uso limitado y estratégico:
Lens.org: útil para revisiones con preguntas acotadas y técnicas (como dispositivos con una función o población bien definida) o para identificar rápidamente autores vinculados a un tema o indicación clínica cuando los métodos estándar no alcanzan.
SpiderCite: complemento para búsquedas de citas en proyectos complejos, siempre que se disponga de artículos semilla.
Copilot (u otros LLMs): apoyo en la generación de palabras clave y términos de búsqueda, pero no para estrategias completas
Conclusión
Las tres herramientas evaluadas (Lens.org, SpiderCite, Copilot) no son adecuadas para reemplazar estrategias de búsqueda complejas en revisiones sistemáticas, debido a variabilidad en sensibilidad y precisión. Sin embargo, tienen potencial como apoyos puntuales en tareas específicas: generación de términos, búsquedas simples o de citas, y exploración preliminar. El estudio subraya la necesidad de mantener el papel central del bibliotecario/experto en información en la validación de cualquier resultado generado con IA, y de continuar monitorizando nuevas herramientas dada la rápida evolución tecnológica.
Reflexiones para quienes trabajamos en bibliotecas médicas
Las herramientas de IA pueden ahorrar tiempo en fases preliminares, generar ideas de términos de búsqueda, identificar autores, pero no deben utilizarse como única estrategia para revisiones sistemáticas si se espera exhaustividad.
Es clave entender los límites: sensibilidad menor, posible sesgo en lo que captura IA, variabilidad según prompt o según lo cerrado o amplio que sea el tema.
Siempre debe haber validación humana experta, verificación de resultados únicos que aparezcan en IA, comparación con lo recuperado por métodos tradicionales.
Las revisiones sistemáticas, consideradas el estándar de oro para responder preguntas clínicas específicas, no están exentas de limitaciones. De hecho, una revisión sistemática refleja las limitaciones de los estudios que incluye, por lo que resulta imprescindible evaluar críticamente cada estudio seleccionado para determinar si puede introducir sesgos en los resultados globales.
Una vez seleccionados los estudios relevantes para una revisión sistemática, el siguiente paso clave es evaluar su calidad metodológica/riesgo de sesgo. Este proceso, lejos de ser neutro o puramente técnico, puede estar sujeto a sesgos de interpretación que afectan tanto la validez de los resultados como la confianza en las conclusiones.
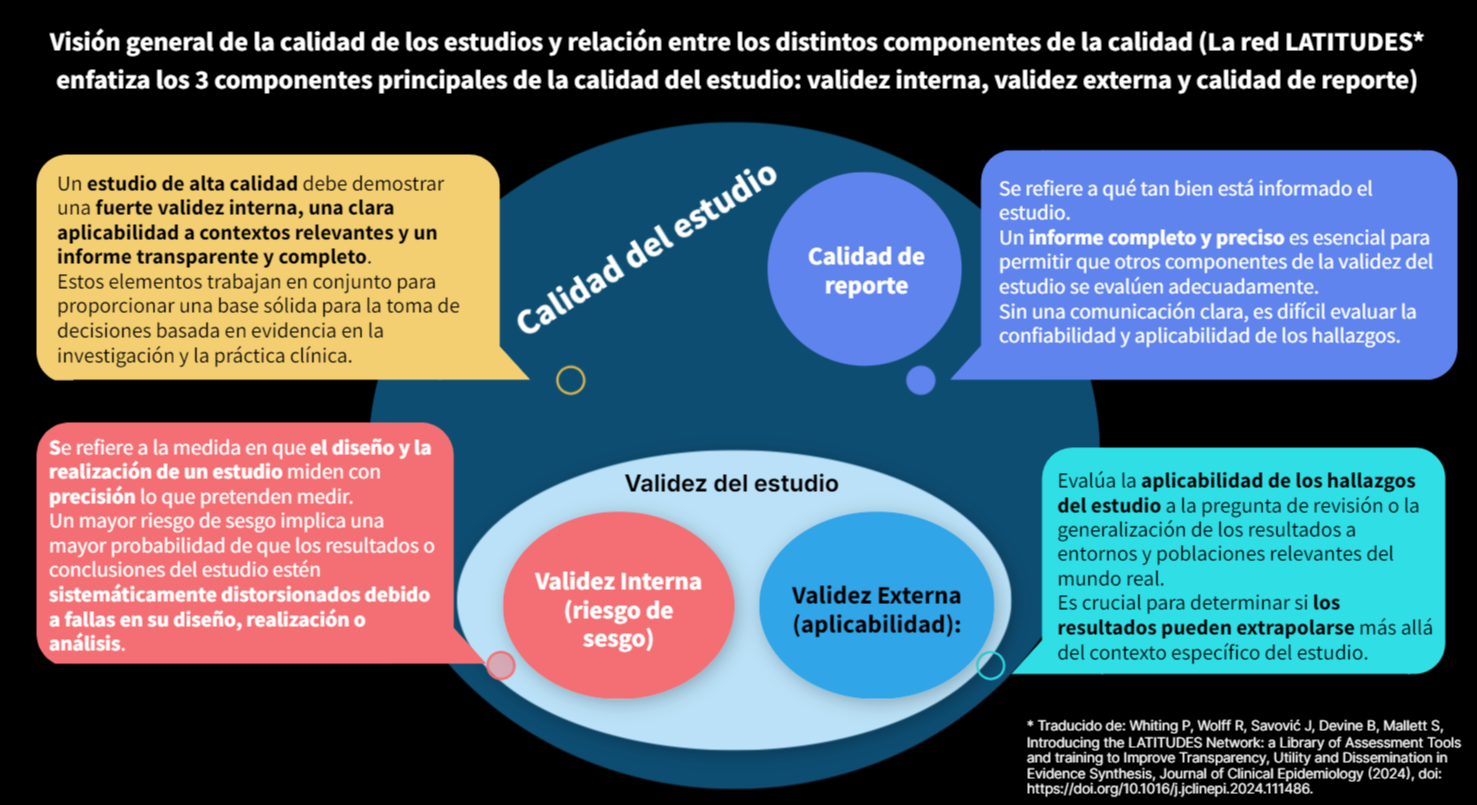
Es importante distinguir entre riesgo de sesgo y calidad metodológica
El riesgo de sesgo se refiere a la posibilidad de que los resultados de un estudio estén sistemáticamente sobrestimados o subestimados debido a errores en su diseño o ejecución. Por ejemplo, un estudio con alta calidad metodológica puede tener alto riesgo de sesgo si, por razones inherentes al diseño, no se pudo aplicar el cegamiento. Del mismo modo, no todas las debilidades metodológicas suponen sesgo: omitir la predeterminación del tamaño muestral puede considerarse una limitación, pero no necesariamente introduce sesgo sistemático.
¿Qué puede sesgar la evaluación de calidad?
El juicio de calidad que emite una persona revisora no siempre es objetivo. Distintos factores pueden influir en su valoración:
Nombre de los autores o afiliaciones institucionales;
Revista donde se publica el estudio;
Resultados del estudio (si son positivos o negativos);
Experiencia previa y formación metodológica del evaluador:
Conflictos de interés, como ocurre cuando quienes evalúan han participado como autores en algunos de los estudios incluidos.
Por ejemplo, Pieper et al. (2018) encontraron que las revisiones sistemáticas en las que los autores de la revisión general también habían participado en alguna de las revisiones incluidas tendían a recibir puntuaciones de mayor calidad.
¿Cómo reducir el sesgo de interpretación?
Existen varias estrategias basadas que pueden ayudar a aumentar la objetividad y transparenciaen la evaluación de calidad:
Usar herramientas estructuradas y validadas
Se recomienda utilizar herramientas formales de evaluación crítica o de riesgo de sesgo, adaptadas al diseño de los estudios incluidos.
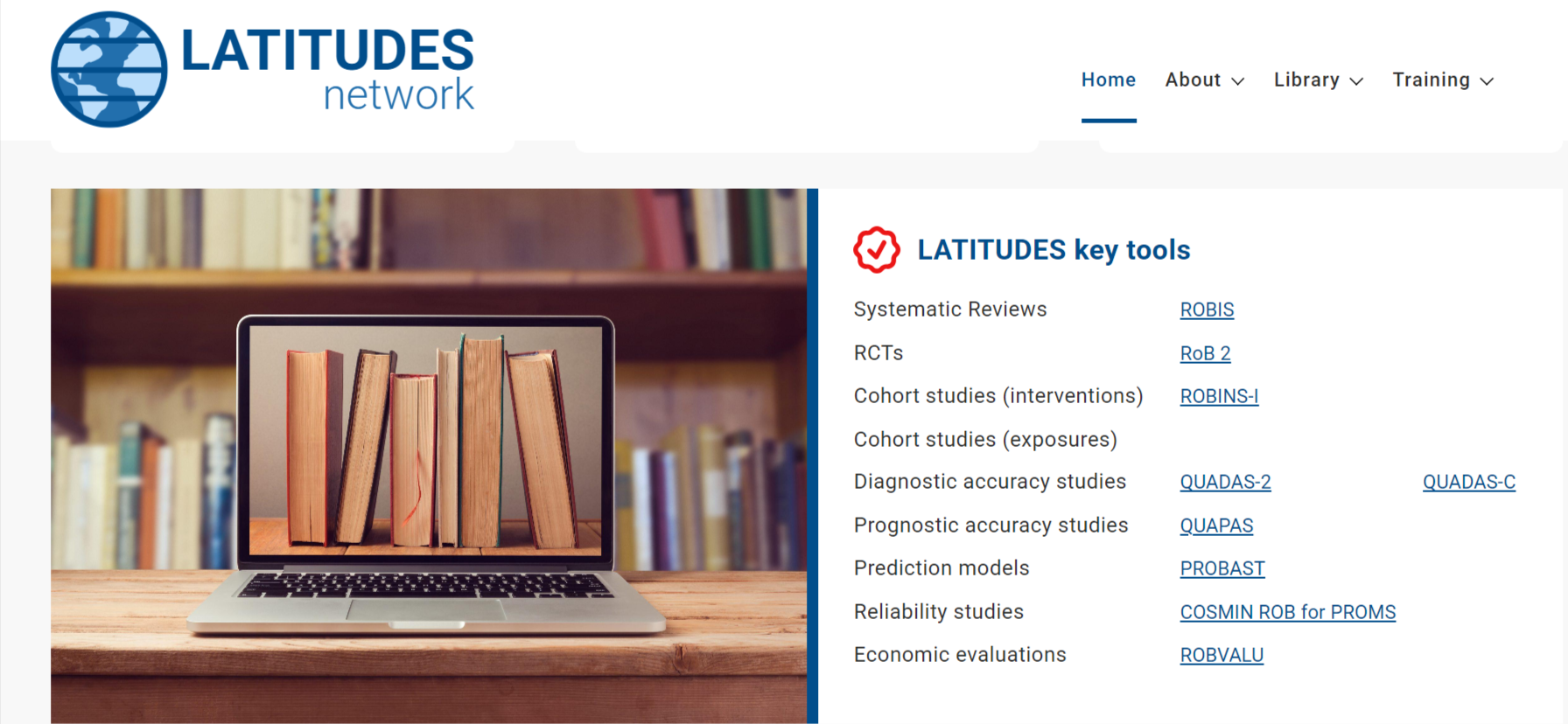
Existen numerosos instrumentos desarrollados en las últimas décadas, lo que puede dificultar la elección. Algunas fuentes útiles para orientar esta decisión son:
El diagrama de flujo proporcionado por LATITUDES es una guía valiosa en este proceso de selección de la herramienta, pero es importante complementarlo con un conocimiento profundo de las características de cada herramienta y las especificidades del estudio en cuestión. Una selección cuidadosa asegura que todos los aspectos relevantes de la calidad del estudio sean evaluados adecuadamente, fortaleciendo así la validez de la síntesis de evidencia.
Evaluación por revisores múltiples
Se sugiere que dos revisores evalúen de forma independiente cada estudio.
Si no es posible una doble evaluación completa, al menos se recomienda que un segundo revisor verifique las evaluaciones realizadas, ya sea en todos los estudios o en una muestra.
Evaluación ciega
Algunas revisiones han experimentado con la evaluación ciega, ocultando nombres de autores y revistas durante la valoración. Sin embargo, los resultados son inconsistentes (Morissette, 2011).
BIBLIOGRAFÍA
Pieper D, Waltering A, Büchter RB. Quality ratings of reviews in overviews: a comparison of reviews with and without dual (co-)authorship. Syst Rev. 2018;7:63; doi: 10.1186/s13643-018-0722-9.
Morissette K, Tricco AC, Horsley T, et al. Blinded versus unblinded assessments of risk of bias in studies included in a systematic review. Cochrane Database of Systematic Reviews 2011;9(MR000025); doi: 10.1002/14651858.MR000025.pub2/full.
La etapa de extracción de datos consiste en obtener, de forma estructurada y rigurosa, la información relevante de los estudios primarios para responder adecuadamente a la pregunta de investigación; es un proceso crítico que no solo asegura la integridad de los hallazgos, sino que también permite una comparación efectiva entre diferentes investigaciones. Dicha información suele proceder de artículos científicos revisados por pares, pero también puede encontrarse en informes regulatorios, protocolos, registros de ensayos, comunicaciones con autores o informes no publicados, cada uno de los cuales aporta un ángulo particular que enriquece la base de datos general. En las revisiones sistemáticas, la unidad de análisis es el estudio, no el informe, lo que significa que es necesario considerar el contexto completo de cada investigación. Por ello, es fundamental identificar y vincular múltiples informes que correspondan a un mismo estudio antes o después de la extracción de datos; este proceso permite evitar la duplicación de información y asegura que se capturen todos los resultados relevantes. Todos estos aspectos se desarrollan en detalle en el Capítulo 5 del Cochrane Handbook for Systematic Reviews of Interventions (1), un recurso clave que proporciona directrices actualizadas sobre cómo llevar a cabo una extracción de datos rigurosa, transparente y reproducible, así como ejemplos prácticos que pueden ayudar a los investigadores a implementar estos procedimientos de manera efectiva en sus propias revisiones sistemáticas.
En dos entradas anteriores de BiblioGetafe, «Evitar sesgos en la búsqueda bibliográfica: claves para revisiones rigurosas» (1) y «Selección de estudios sin sesgos en revisiones sistemáticas: 6 principios y 4 consejos» (2), analizamos los sesgos en las etapas de búsqueda bibliográfica y selección de estudios. En esta entrada, revisamos los errores más frecuentes que pueden surgir en la extracción de datos, su impacto sobre los resultados de la revisión y las mejores prácticas para minimizarlos y garantizar la fiabilidad del proceso. Estos errores pueden incluir desde la mala interpretación de las fuentes de datos hasta la manipulación incorrecta de los mismos, lo que puede llevar a conclusiones erróneas y, en última instancia, a decisiones inadecuadas. Para abordar estos desafíos, es fundamental identificar las causas de los errores y aplicar estrategias efectivas, como la implementación de controles de calidad rigurosos, la capacitación adecuada del personal involucrado y el uso de herramientas de software avanzadas que faciliten una extracción de datos más precisa y eficiente. De este modo, se puede mejorar significativamente la integridad y la validez de los resultados obtenidos, contribuyendo a un proceso de análisis más robusto y confiable.
Errores frecuentes
La extracción de datos no está libre de riesgos. Estos pueden deberse a:
Mala interpretación de los datos presentados en los estudios.
Omisión de variables relevantes.
Errores en la recogida de datos clave como el número de participantes, medias, desviaciones estándar o tamaños del efecto (3-5).
Una revisión metodológica identificó tasas de error en la extracción de datos que oscilan entre el 8% y el 70%, dependiendo del tipo de desenlace y del diseño de la revisión (5). Afortunadamente, la mayoría de los estudios concluyen que estos errores suelen tener un impacto bajo o moderado en los resultados globales de la revisión (5-6).
¿Cómo reducir los errores?
Existen varias estrategias recomendadas:
Uso de formularios estructurados: ayudan a definir de forma clara qué datos deben extraerse y cómo codificarlos. Los autores de revisiones suelen tener distintos perfiles profesionales y niveles de experiencia en revisiones sistemáticas. El uso de un formulario de extracción de datos contribuye a garantizar cierta consistencia en el proceso de recogida de información y resulta imprescindible para comparar los datos extraídos por duplicado. Es recomendable realizar una prueba piloto de los formularios mediante una muestra representativa de los estudios que se van a revisar, comparando extracciones independientes de varios revisores sobre un pequeño número de estudios (3). Como mínimo, el formulario de extracción de datos (o una versión muy similar) debe haber sido evaluado en cuanto a su usabilidad.
Doble extracción de datos: Es importante proporcionar instrucciones detalladas a todos los revisores que utilizarán el formulario de obtención de datos. Al menos dos personas deben extraer de forma independiente la información para disminuir los errores y reducir los sesgos potenciales. La duplicación es especialmente importante para los datos de desenlaces, ya que estos alimentan directamente la síntesis de la evidencia y, en consecuencia, las conclusiones de la revisión. En caso de desacuerdo, el equipo ha de discutir la información extraída de cada uno de los artículos hasta llegar al acuerdo. Duplicar el proceso de extracción de datos reduce tanto el riesgo de cometer errores como la posibilidad de que la selección de datos se vea influida por los sesgos de una sola persona. Se ha demostrado que realizar la extracción de forma independiente por dos revisores reduce significativamente los errores, frente a la extracción por un único revisor con o sin verificación posterior (5). Si no es posible el doble proceso, al menos debería realizarse una verificación independiente de los datos extraídos, ya sea sobre una muestra o sobre todos los estudios incluidos.
Mayor rigor en datos sensibles: se aconseja prestar especial atención a la información que requiere interpretación subjetiva y a los datos críticos para la síntesis, como los resultados principales. En estos casos, se justifica un proceso de extracción más exhaustivo (3).
Tabla resumen de las estrategias para reducir errores en la extracción de datos
Estrategia
Descripción
Mejora
Referencia
Uso de formulario estructurado
Define claramente qué datos extraer y cómo codificarlos
Mejora la consistencia y precisión
Li et al., 2024
Pilotaje del formulario
Prueba piloto previa con varios revisores sobre algunos estudios
Identifica instrucciones ambiguas o errores
Li et al., 2024
Doble extracción independiente
Dos revisores extraen datos por separado
Reduce significativamente los errores y sesgos
Mathes et al., 2017
Verificación por segundo revisor (si no hay doble)
Revisión de una muestra o del total por otro revisor
Detecta errores no evidentes
Mathes et al., 2017
Rigor adicional para datos clave o subjetivos
Más control en la extracción de resultados primarios o interpretativos
Li T, Higgins JPT, Deeks JJ. Chapter 5: Collecting data [last updated October 2019]. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.5. Cochrane, 2024. Available from cochrane.org/handbook.
Gøtzsche PC, Hróbjartsson A, Marić K, Tendal B. Data extraction errors in meta-analyses that use standardized mean differences. JAMA. 2007;298(4):430–7.
Mathes T, Klaßen P, Pieper D. Frequency of data extraction errors and methods to increase data extraction quality: a methodological review. BMC Med Res Methodol. 2017;17(1):152.
Buscemi N, Hartling L, Vandermeer B, Tjosvold L, Klassen TP. Single data extraction generated more errors than double data extraction in systematic reviews. J Clin Epidemiol. 2006;59(7):697–703.
La base de toda revisión sistemática y otros estudios de síntesis sólidos es una búsqueda de evidencia cuidadosamente diseñada y rigurosamente ejecutada (1). En la búsqueda bibliográfica cómo se busca, dónde se busca y quién diseña la estrategia son factores que pueden marcar una diferencia crítica en la calidad de la evidencia recopilada.
En el proceso de búsqueda pueden surgir dos tipos principales de sesgos:
Sesgo de identificación: aparece cuando no se localizan estudios relevantes, a menudo porque la estrategia de búsqueda no es suficientemente sensible o porque no se han explorado todas las fuentes pertinentes. Este tipo de sesgo es especialmente problemático en revisiones sistemáticas que sirven de base para tomar decisiones clínicas, ya que puede comprometer la validez de los resultados.
Sesgo de diseminación (o de publicación): se produce cuando los resultados de un estudio influyen en su probabilidad de ser publicados. Por ejemplo, los estudios con resultados positivos tienen más probabilidades de publicarse, de hacerlo en inglés, con mayor rapidez o de recibir más citas. Este fenómeno puede distorsionar la percepción de la eficacia de una intervención.
¿Cómo reducir estos sesgos?
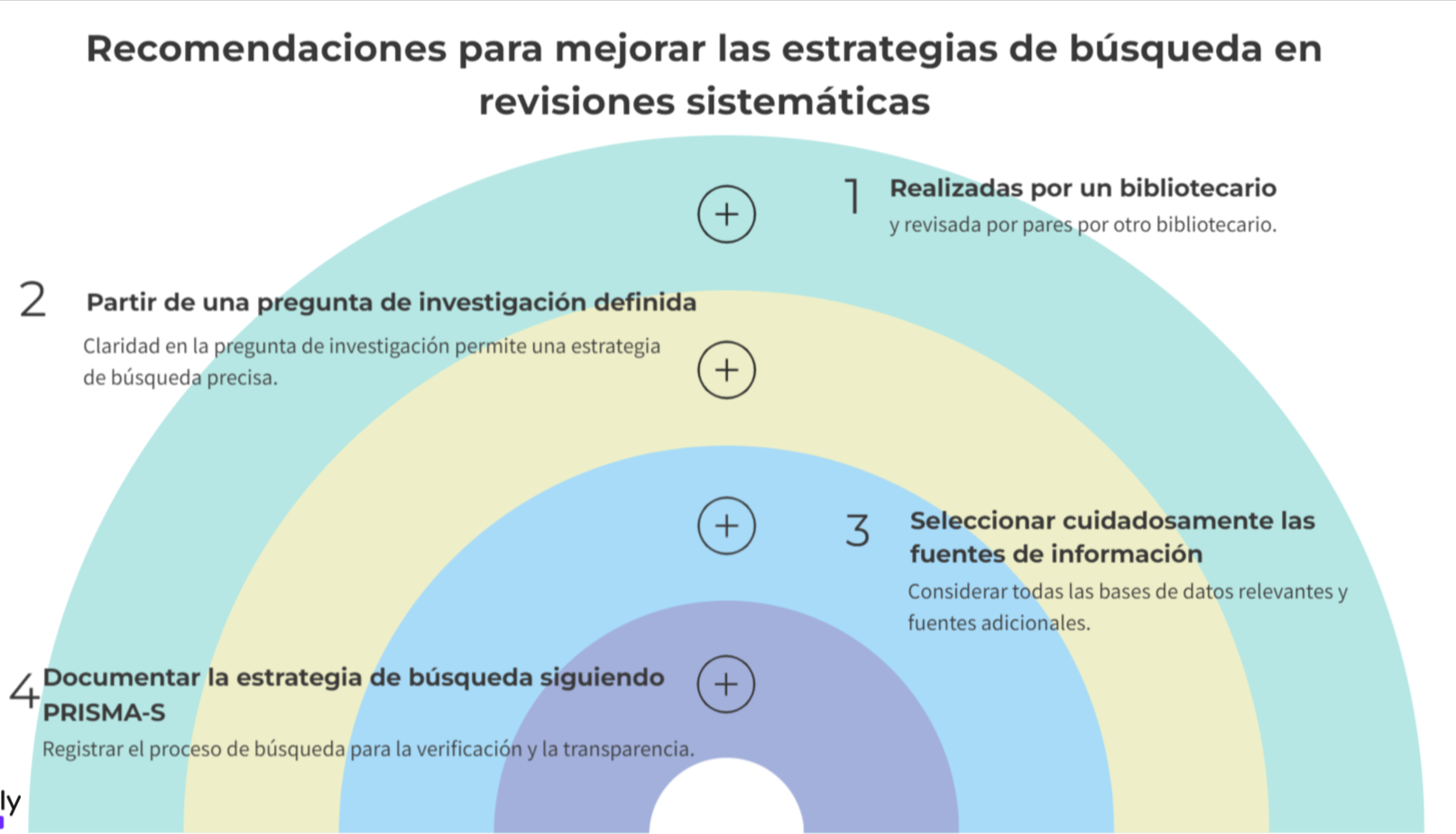
Diseñar una estrategia de búsqueda rigurosa, con la colaboración de un especialista en información. Idealmente, esta estrategia debe ser revisada por pares antes de ser ejecutada (1,4-6). La participación de bibliotecarios especializados en ciencias de la salud en revisiones sistemáticas no es un añadido opcional, sino una práctica recomendada por las principales guías metodológicas (7-9) y respaldada por la evidencia científica (10-11).
Utilizar múltiples bases de datos bibliográficas. Se recomienda un mínimo de dos para revisiones sistemáticas, pero también se debe justificar su elección. Según el Cochrane Handbook, el objetivo de las búsquedas es identificar todos los estudios relevantes disponibles, lo que requiere desarrollar estrategias lo más sensibles posibles, sin perder de vista la pertinencia de los resultados (7). Debemos hacer balance entre la precisión y exhaustividad pero teniendo en cuenta que el objetivo de una búsqueda para una RS es identificar todos los estudios pertinentes (maximizar la sensibilidad pero con una precisión razonable). Una de las cuestiones más complicadas es cuando dar por finalizada la búsqueda. En este equilibrio entre amplitud y relevancia, la experiencia del bibliotecario resulta fundamental.
Ampliar la búsqueda más allá de las bases de datos. La inclusión de fuentes como motores de búsqueda, registros de ensayos clínicos, literatura gris, búsqueda complementaria de citas (forward y backward) y el contacto con expertos puede ser clave para identificar estudios que de otro modo pasarían desapercibidos.
Incluir estudios no publicados. Dado que una parte significativa de los estudios completados no se publican (12), buscarlos activamente en registros, literatura gris o sitios web especializados contribuye a mitigar el sesgo de publicación (13).
Tipo de sesgo
Descripción
Estrategias para minimizarlo
Sesgo de identificación
No se recuperan todos los estudios relevantes.
Diseñar una estrategia exhaustiva con ayuda de un bibliotecario experto Usar ≥2 bases de datos Evitar el uso uso de filtros/límites Ampliar con búsquedas complementarias
Sesgo de publicación o diseminación
Solo se publican ciertos tipos de resultados, como los positivos.
Buscar literatura gris Consultar registros de ensayos clínicos Contactar expertos Incluir estudios no publicados
Un dato revelador
Greenhalgh y Peacock (14) encontraron que solo el 25% de los artículos incluidos en su revisión fueron recuperados a través de bases de datos electrónicas. El resto provino de rastrear citas, conocimiento personal, contactos o búsqueda manual.
BIBLIOGRAFÍA
Metzendorf MI, Featherstone RM. Ensuring quality as the basis of evidence synthesis: leveraging information specialists’ knowledge, skills, and expertise. Cochrane Database of Systematic Reviews 2018, Issue 9. Art. No.: ED000125. doi: 10.1002/14651858.ED000125.
McGowan J, Sampson M. Systematic reviews need systematic searchers. JMLA 2005;93(1):74–80.
Rethlefsen ML, Farrell AM, Osterhaus Trzasko LC, Brigham TJ. Librarian co‐authors correlated with higher quality reported search strategies in general internal medicine systematic reviews. Journal of Clinical Epidemiology2015;68(6):617–26. doi: 10.1016/j.jclinepi.2014.11.025
McGowan J. Sampson M, Salzwedel DM, Cogo E, Foerster V, Lefebvre C. PRESS peer review of electronic search strategies: 2015 guideline statement. J Clin Epidemiol. 2016.75:40–46. doi: 10.1016/j.jclinepi.2016.01.021
Lefebvre C, Manheimer E, Glanville J. Chapter 6: Searching for studies. In: Higgins JPT, Green S. (Editors). Cochrane handbook for systematic reviews of interventions version 5.1.0. Updated March 2011. Accessed July 27, 2022. https://handbook-5-1.cochrane.org/chapter_6/6_searching_for_studies.htm
Aromataris E, Munn Z. Chapter 1: JBI systematic reviews. In: Aromataris E, Munn Z (Editors).In: JBI Manual for Evidence Synthesis. JBI; 2020. Accessed July 27, 2022. https://jbi-global-wiki.refined.site/space/MANUAL
Kugley S, Wade A, Thomas J, et al. Searching for studies: a guide to information retrieval for Campbell Systematic Reviews. Oslo: The Campbell Collaboration; 2017. Accessed July 27, 2022. doi: 10.4073/cmg.2016.1
Rethlefsen ML, Murad MH, Livingston EH. Engaging medical librarians to improve the quality of review articles. JAMA. 2014;312(10):999-1000. doi:10.1001/jama.2014.9263
Kirtley S. Increasing value and reducing waste in biomedical research: librarians are listening and are part of the answer. Lancet. 2016;387(10028):1601. doi:10.1016/S0140-6736(16)30241-0
Hong QN, Brunton G. Helping Trainees Understand the Strategies to Minimize Errors and Biases in Systematic Review Approaches. Educ Information. 2025;41(3):161–175; doi: 10.1177/01678329251323445.
Greenhalgh, T., & Peacock, R. (2005). Effectiveness and efficiency of search methods in systematic reviews of complex evidence: Audit of primary sources. BMJ. 2005:331(7524), 1064–1065. doi: 10.1136/bmj.38636.593461.68
En otras entradas de este blog hemos hablado de la importancia de planificar correctamente una revisión sistemática, como en los 13 pasos para la planificación de una revisión o en la explicación de la metodología de búsqueda según JBI. Hoy ponemos el foco en un momento clave del proceso: el primer paso que da el bibliotecario cuando comienza a colaborar en una revisión sistemática.
Antes de diseñar la estrategia de búsqueda definitiva, es imprescindible realizar una búsqueda preliminar exploratoria, identificar revisiones en curso en registros como PROSPERO y, a partir de todo ello, refinar y delimitar adecuadamente la pregunta de investigación. Esta fase inicial es fundamental para asegurar la pertinencia del trabajo, evitar duplicaciones y aportar valor a la evidencia existente.
Estos primeros pasos no siempre son visibles, pero son esenciales para que la revisión tenga solidez metodológica desde el inicio. El papel del bibliotecario en esta fase no solo es técnico, sino estratégico: contribuye activamente a que el equipo investigador formule una pregunta clara, contextualizada y alineada con la literatura disponible. Como se muestra en la imagen, incluso las herramientas de IA generativa pueden ser un apoyo en esta etapa exploratoria, aunque siempre deben usarse de forma crítica y complementaria, nunca como sustituto de las fuentes especializadas.
El pasado martes tuve el placer de impartir el curso “Fundamentos metodológicos de revisiones sistemáticas”, organizado por BiblioSalud, la red de bibliotecarios y profesionales de la información en ciencias de la salud de España. Esta sesión formativa, dirigida especialmente a bibliotecarios médicos, se centró en los aspectos clave que debemos conocer para comprender y acompañar con rigor el desarrollo de una revisión sistemática.
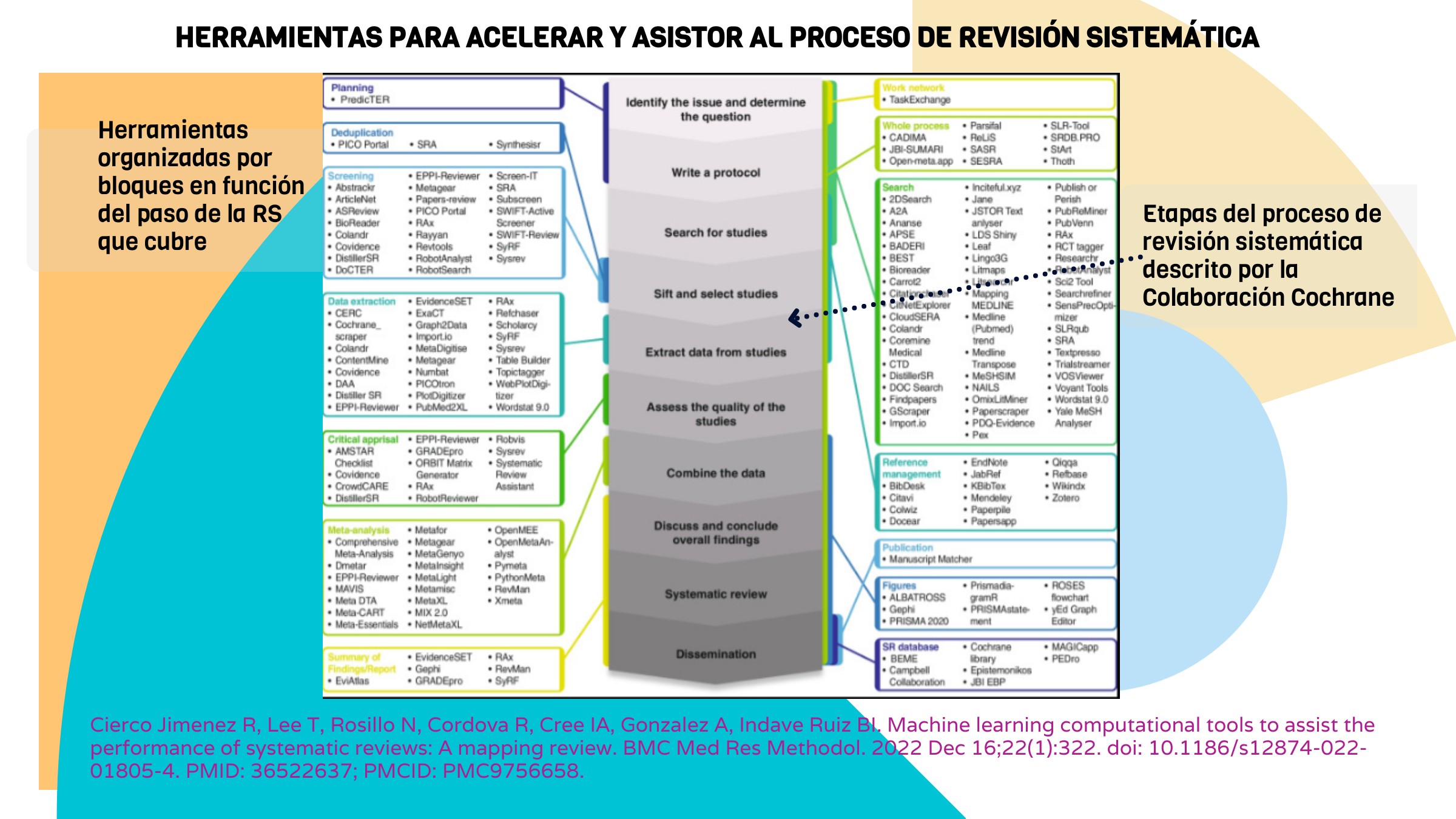
En esta entrada del blog quiero comenzar a compartir una selección de las herramientas y recomendaciones prácticas que utilizo habitualmente en mi trabajo diario con documentos de síntesis de evidencia.
El objetivo es ofrecer una guía no exhaustiva, hay muchas y variadas (ver figura) pero con recomendaciones y herramientas útiles y basada en mi experiencia, que sirva tanto a quienes empiezan como a quienes ya participan en revisiones sistemáticas desde las bibliotecas.
Voy a dividir las herramientas en varios apartados según su uso:
Recolección de términos controlados y libres.
Proceso de búsqueda y cribado.
Chatbots e inteligencia artificial para apoyar la confección de estrategias booleanas.
Herramientas para la búsqueda complementaria.
Otras herramientas recomendadas para las revisiones sistemáticas.
En esta entrada veremos las primeras de estas herramientas y recomendaciones para la recolección de términos.
Recolección de términos
Uno de los pasos más críticos en cualquier revisión sistemática es la correcta identificación de términos controlados y palabras clave. Una estrategia de búsqueda bien construida comienza con una recolección exhaustiva de términos y para ello contamos con una serie de recursos imprescindibles:
1.1. Entry Terms de MeSH Database.
La herramienta clásica para explorar la jerarquía de los Medical Subject Headings (MeSH). Nos permite ver la definición de cada término, sus sinónimos, su posición dentro del árbol jerárquico, subencabezamientos permitidos y términos relacionados o «Entry Terms». Fundamental para identificar los términos controlados exactos que se deben utilizar en PubMed y para entender el enfoque conceptual con el que el sistema indexa los documentos.
1.2. Sinónimos de Emtree de EMBASE
El Emtree es el tesauro específico de la base de datos Embase. Su lógica es similar al MeSH pero tiene su propia estructura y contiene más términos, especialmente útiles para temas en farmacología o dispositivos médicos. Conviene hacer búsquedas paralelas en MeSH y Emtree para comparar coberturas y encontrar sinónimos o variantes terminológicas que pueden enriquecer la estrategia.
Esta herramienta permite comparar los términos MeSH asignados, los términos empleados en el título y resumen así como las palabras clave de los autores a un conjunto de artículos. Es especialmente útil para detectar patrones o términos recurrentes en la literatura más relevante sobre tu tema. Solo necesitas extraer los PMIDs de los artículos clave y el analizador los agrupa mostrando visualmente los MeSH comunes. Ideal para verificar si estás pasando por alto términos relevantes o para ajustar tu estrategia inicial.
Esta herramienta permite analizar la frecuencia de palabras en títulos y resúmenes de los resultados de una búsqueda bibliográfica. Solo necesitas copiar y pegar el listado de referencias (por ejemplo, desde PubMed) y Word Freq generará un listado de términos ordenados por frecuencia. Es especialmente útil para:
Identificar términos clave y sinónimos que puedes haber pasado por alto.
Detectar conceptos emergentes o patrones de lenguaje en la literatura.
Afinar tu estrategia de búsqueda ajustando los términos libres.
Una herramienta sencilla pero muy eficaz para enriquecer la fase exploratoria de cualquier revisión sistemática.
Es una potente herramienta para realizar minería de datos sobre resultados de PubMed. Introduciendo una lista de PMIDs o haciendo una búsqueda directa, puedes ver las frecuencias de palabras en títulos, resúmenes y términos MeSH. También puedes analizar la aparición de autores, revistas, años de publicación… Es perfecta para afinar términos libres y obtener una imagen más clara del contexto bibliográfico.
Desarrollado por la National Library of Medicine, este recurso es especialmente útil cuando partimos de un texto breve (como el resumen de un protocolo o el título de un artículo). Solo tienes que copiar el contenido y MeSH on Demand te devuelve sugerencias de términos MeSH relevantes. Es una excelente forma de inspirarte cuando aún estás perfilando la estrategia inicial.
1.7. Asistente de inteligencia artificial MeshMaster
MeSHMaster es un chatbot especializado que utiliza inteligencia artificial para ayudarte a construir estrategias de búsqueda booleanas, combinando términos MeSH y palabras clave libres. A partir de una descripción breve del tema o una pregunta clínica, el asistente sugiere:
Términos MeSH relevantes y sinónimos.
Combinaciones booleanas iniciales (AND, OR, NOT).
Variantes terminológicas en inglés que pueden enriquecer la sensibilidad de la búsqueda.
Es una herramienta especialmente útil en las primeras fases de diseño de la estrategia, cuando se busca inspiración o una validación rápida de conceptos clave. Aporta rapidez sin perder la lógica estructural que requiere una buena estrategia de búsqueda.
Te invito a seguir mis próximas entradas para descubrir cómo integrar estas herramientas en tu revisión sistemática.
La evaluación de la calidad de la evidencia en revisiones sistemáticas (RS) es esencial para la toma de decisiones. Aunque el sistema GRADE (Grading of Recommendations Assessment, Development and Evaluation) ofrece un enfoque consolidado para calificar el nivel de evidencia, su aplicación es compleja y requiere mucho tiempo. La inteligencia artificial (IA) puede utilizarse para superar estas barreras.
En este contexto, acaba de publicarse un estudio experimental analítico que busca desarrollar y evaluar la herramienta URSE basada en IA para la semiautomatización de una adaptación del sistema de clasificación GRADE, determinando niveles de evidencia en RS con metaanálisis compilados de ensayos clínicos aleatorizados (1).
Las conclusiones de este estudio revelan que el rendimiento del sistema GRADE automatizado URSE es insatisfactorio en comparación con los evaluadores humanos. Este resultado indica que el objetivo de utilizar la IA para GRADE no se ha alcanzado.
Las limitaciones del sistema GRADE automatizado URSE reforzaron la tesis de que las herramientas potenciadas por IA deben utilizarse como una ayuda para el trabajo humano y no como un sustituto del mismo. En este contexto, el sistema GRADE automatizado URSE puede utilizarse como segundo o tercer revisor, lo que mejora la objetividad de las dimensiones GRADE, reduce el tiempo de trabajo y resuelve discrepancias.
Los resultados demuestran el uso potencial de la IA en la evaluación de la calidad de la evidencia. Sin embargo, considerando el énfasis del enfoque GRADE en la subjetividad y la comprensión del contexto de producción de evidencia, la automatización completa del proceso de clasificación no es oportuna. No obstante, la combinación del sistema GRADE automatizado URSE con la evaluación humana o la integración de esta herramienta en otras plataformas representa direcciones interesantes para el futuro.
En el siguiente enlace encontrarás un resumen del artículo:
https://hacia-la-automatizacion--1z75d14.gamma.site/
BIBLIOGRAFÍA
Oliveira dos Santos A, Belo VS, Mota Machado T, et al. Toward automating GRADE classification: a proof-of-concept evaluation of an artificial intelligence-based tool for semiautomated evidence quality rating in systematic reviews. BMJ Evidence-Based Medicine. 2025. doi: 10.1136/bmjebm-2024-113123
Las herramientas de inteligencia artificial aumentan significativamente la eficiencia y la precisión en tareas repetitivas, permitiendo a los investigadores concentrarse en la generación de ideas y el análisis crítico. Las herramientas de IA facilitan el descubrimiento de patrones complejos en grandes volúmenes de datos que serían difíciles de identificar mediante métodos tradicionales.
Estas herramientas pueden acelerar significativamente el proceso de producción o actualización de síntesis de evidencia, lo que beneficia tanto a investigadores como a usuarios. Sin embargo, comprender las fortalezas y limitaciones de estas tecnologías es fundamental para mantener la calidad.
La inteligencia artificial no reemplaza el juicio experto; sin embargo, tiene la capacidad de potenciarlo de maneras significativas y, en algunos casos, puede distorsionarlo de formas inesperadas.
Todos aquellos involucrados en la metodología de las revisiones sistemáticas deben ponerse al día en el uso de la IA. Porque ya no se trata de una idea futura: está ocurriendo ahora, en tiempo real.
En esta entrada voy a dar una visión panorámica de cómo la IA puede intervenir en las diferentes fases del proceso de una revisión sistemática.
Fase por fase: promesas y preguntas
Figura 1. Fases de una revisión sistemática en las que puede intervenir la inteligecia artificial.
En una reciente revisión de alcance de Lieberum et al. (1) incluía 37 artículos del uso de LLM (modelo de lenguaje de gran tamaño) como apoyo en 10 de 13 pasos de las revisiones sistemáticas (ver figura 2).
Como vemos, es en las fases de búsqueda de literatura (41%) , selección de estudios (38%) y extracción de datos (30%) donde hay más estudios publicados. De todas las LLM utilizadas, es GPT (Generative Pretrained Transformer) el más empleado (89%). En la mitad de los estudios, los autores valoran los LLM como prometedores (54%).
Figura 3. Gráfico que muestra las proporciones de los pasos de la RS. Pasos de la RS (capa interna de pastel) y las aplicaciones asociadas de modelos de lenguaje grande (MLG) (capa externa de donut).
¿Puede la IA diseñar estrategias de búsqueda?
Garantizar la «reproducibilidad«, que es la piedra angular de la investigación académica y las búsquedas de literatura, como lo demuestran el enfoque de doble revisión descritos en las directrices de PRISMA. Las herramientas actuales de IA se quedan cortas en precisión y sensibilidad. Además, los usuarios pueden hacer los motores de búsqueda de IA la misma pregunta varias veces y recibir diferentes respuestas informadas por diferentes fuentes.
Aunque los LLM parecen ser potencialmente útiles como punto de partida, se necesita experiencia para revisar/supervisar/ contextualizar los outputs. En las tareas que requieren mucho tiempo, como la actualización de las búsquedas pueden automatizarse parcialmente. La IA «no es de gran ayuda» para los pasos «mecánicos» de una búsqueda (ejecución, exportación, importación). Por otro lado, las bases de datos de suscripción juegan un papel importante y restringen la posibilidad de automatización. Puede ser útil como punto de partida para el desarrollo de estrategias de búsqueda, pero no como un método único, sin ser auditado por un especialista en búsqueda de información.
Herramientas de búsquedas basadas en IA como Elicit, Consensus y el ChatGPT son inexactos y carecen de comprensión en comparación con las búsquedas de literatura iniciadas por humanos (2). Estas herramientas deben evolucionar más allá de la simple identificación de palabras clave hacia una comprensión matizada de la jerarquía académica y el contexto. Por lo tanto, la integración de la IA en las búsquedas de literatura para revisiones sistemáticas exige mejoras sustanciales en su comprensión del contexto y la jerarquía, en el cumplimiento del criterio de reproducibilidad y alinearse con los rigurosos estándares de las revisiones sistemáticas realizadas por los humanos.
Tras más de 35 años buscando información científica, puedo afirmar que nunca hemos experimentado una transformación como la que nos ofrece la inteligencia artificial. Es el momento de aprovechar esta oportunidad y ser parte del cambio que está revolucionando nuestro mundo. En conclusión, podemos decir: No puede reemplazar a los especialistas en información «todavía» …
Cuestiones éticas: la parte menos visible
El uso ético de ChatGPT y otros sistemas de LLM es un tema de debate académico y público. Aspectos que debemos reflexionar y tener en consideración:
Las herramientas de IA están desarrolladas, en su mayoría, por empresas privadas.
Los autores deben ser responsables de la revisión de literatura, no la IA. Es imprescindible mantener principios de transparencia sobre el uso de herramientas de IA y responsabilidad en la verificación de la información generada. Los investigadores deben establecer prácticas claras para citar apropiadamente el trabajo asistido por IA y garantizar que las contribuciones humanas y artificiales sean debidamente reconocidas.
El uso sin crítica puede llevar a la propagación de información falsa en la investigación.
La búsqueda con IA generativa utiliza al menos 4 a 5 veces más poder computacional que la búsqueda estándar (3). Debemos reconocer los impactos ambientales y promover un uso responsable y sostenible de los LLMs para tareas específicas en la síntesis de evidencia y la búsqueda.
BIBLIOGRAFÍA
Lieberum JL, Töws M, Metzendorf MI, Heilmeyer F, Siemens W, Haverkamp C, Böhringer D, Meerpohl JJ, Eisele-Metzger A. Large language models for conducting systematic reviews: on the rise, but not yet ready for use-a scoping review. J Clin Epidemiol. 2025 Feb 26;181:111746. doi: 10.1016/j.jclinepi.2025.111746.
Seth I., Lim B., Xie Y., Ross RJ., Cuomo R., Rozen WM. Artificial intelligence versus human researcher performance for systematic literature searches: a study focusing on the surgical management of base of thumb arthritis. Plast Aesthet Res. 2025, doi: 10.20517/2347-9264.2024.99.
Características de las búsquedas para revisiones sistemáticas
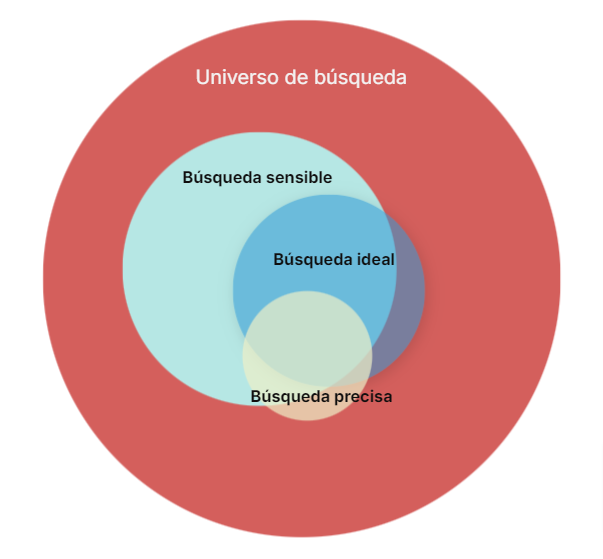
Las revisiones sistemáticas requieren estrategias de búsqueda rigurosas (que identifiquen todos los registros relevantes, pero no tan amplia como para que haya demasiados artículos irrelevantes), transparentes y reproducibles (documentando los pasos que se dieron durante la búsqueda) de tal forma que permita que los futuros equipos de investigación se basen en el trabajo de la revisión sistemática (RS), así como también lo evalúen, valoren y critiquen.
Las revisiones sistemáticas requieren una búsqueda sistemática. Dada la complejidad de los lenguajes y reglas de indexación de las diversas bases de datos, la mejor manera para que el equipo de investigación asegure el rigor de la búsqueda es incluir un bibliotecario en el equipo de revisión.
Retos en la búsqueda de evidencia
El primer elemento de una revisión sistemática es la propia pregunta. La pregunta determinará el desarrollo de la estrategia de búsqueda y qué tipo de estudios se encontrarán. Si la pregunta no es lo suficientemente clara en este punto, es posible que no se detecten artículos que puedan ser de interés o que se encuentren muchos artículos que no son lo que se quiere.
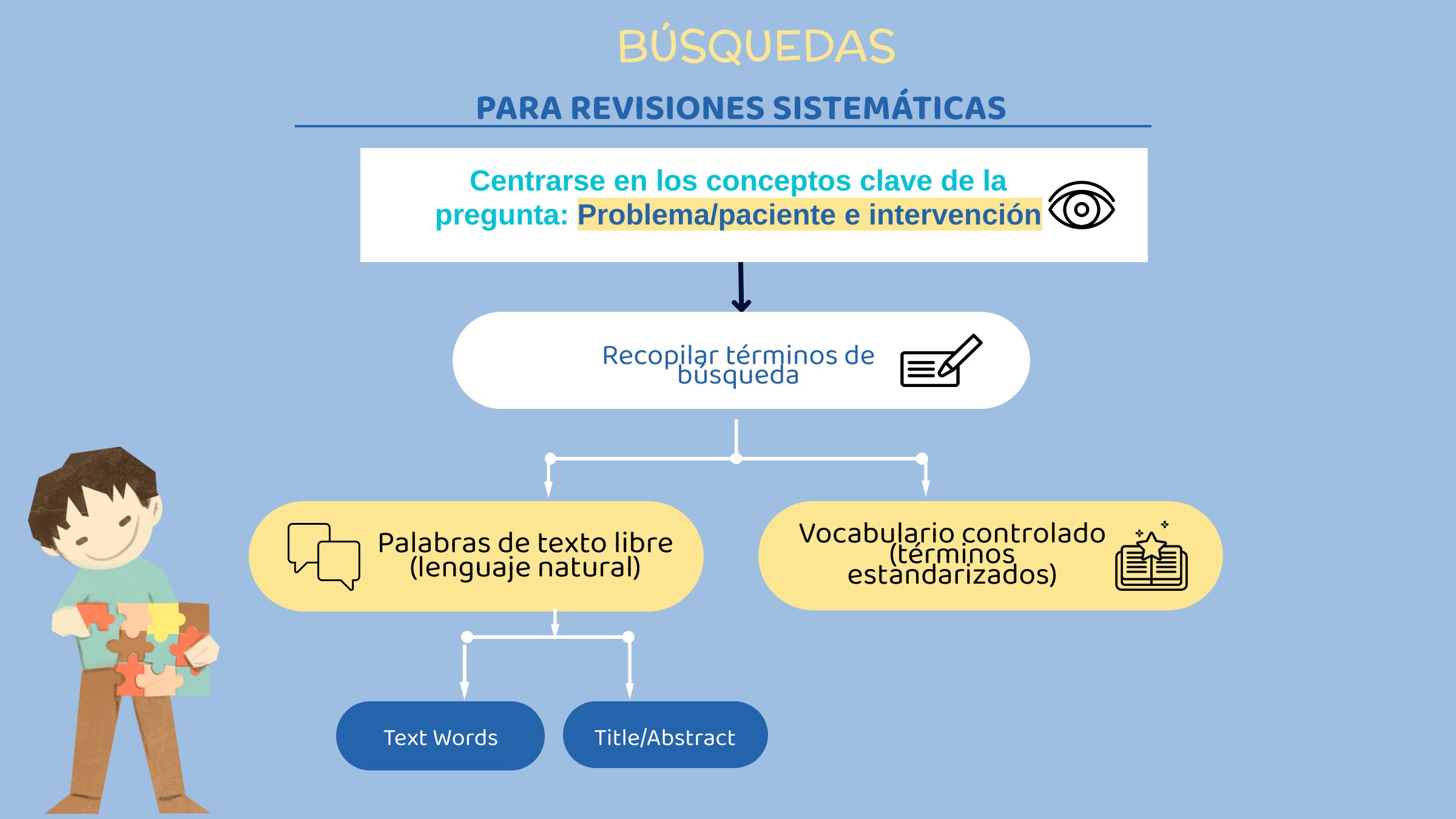
Traslado de la pregunta de investigación a la estrategia de búsqueda. La pregunta es el punto de partida para estructurar una estrategia de búsqueda, es la de identificar los principales conceptos de la pregunta clínica (generalmente en un formato PICO para revisiones de intervención y PEO para revisiones de factores de riesgo). Los errores más comunes para traducir una pregunta de investigación en un plan de búsqueda incluyen perder un concepto importante y agregar demasiados conceptos. (ver entrada «¿Debo incluir los Resultados (Outcomes) en la estrategia de búsqueda de una revisión sistemática?«).
Aplicar límites. de forma segura para evitar sesgos y disminución de la sensibilidad. Los límites más empleados son los límites temporal, de idiomas o de acceso al texto completo gratuito pero estos solo se deben incluir en la estrategia si está justificado metodológicamente. La mejor manera de aplicar límites es hacerlo de tal manera que la búsqueda incluya registros indexados por un límite deseado sin faltar registros que cumplan con esa misma descripción pero que no se indexan de esa manera. Esto se puede lograr mediante el uso cuidadoso del operador booleano NOT (por ejemplo, para eliminar estudios animales y quedarnos solo con estudios en humanos). Ver entrada «¿Cómo limitamos el resultado de una búsqueda bibliográfica a solo humanos?: Recomendación para búsqueda en revisiones sistemáticas«. También debemos tener presente la utilización de los llamados filtros de búsqueda (ver entrada: «Qué son los filtros de búsqueda y principales herramientas para su localización«).
Errores comunes en las estrategias de búsqueda en revisiones sistemáticas
Errores en la selección de las fuentes de búsqueda
La producción de una revisión sistemática requiere la búsqueda sistemática en varias bases de datos bibliográficas. Se desconoce el número óptimo de bases de datos que hay que consultar, sin embargo, buscar en una sola base de datos no es suficiente, aunque no existe evidencia de la cantidad de bases de datos en las que se debe buscar. Una sola base de datos no representa todas las investigaciones potencialmente relevantes que existen. Al elegir incluir solamente una base de datos, el revisor está introduciendo un sesgo de selección en esta etapa temprana del proceso de revisión. La búsqueda solo de PubMed y Embase recupera el 71.5% de las publicaciones incluidas, mientras que agregar bases de datos adicionales a las estrategias de búsqueda aumenta la recuperación al 94.2% (el 5.8% de las referencias no se recuperan en ninguna base de datos) (Frandsen TF, Moos C, Linnemann Herrera Marino CI, Brandt Eriksen M, Supplementary databases increased literature search coverage beyond PubMed and Embase, Journal of Clinical Epidemiology (2025), doi: https://doi.org/10.1016/j.jclinepi.2025.111704.). Ver entrada «En qué bases de datos debemos buscar para una revisión sistemática: La producción de una revisión sistemática requiere la búsqueda sistemática en varias bases de datos bibliográficas.»En qué bases de datos debemos buscar para una revisión sistemática: La producción de una revisión sistemática requiere la búsqueda sistemática en varias bases de datos bibliográficas» y «Cobertura y solapamiento de las bases de datos utilizadas en las revisiones sistemáticas de ciencias de la salud«).
La búsqueda ha de realizarse en bases de datos automatizadas, pero también ha de incluirse búsquedas que complementen esta, como es la búsqueda de literatura gris. Si uno realmente quiere localizar toda la evidencia que hay no puede detenerse en la búsqueda de las principales bases de datos.
Insuficiente amplitud o sensibilidad de la búsqueda
La estrategia de búsqueda ha de ser una combinación de términos del lenguaje natural (campo de título y abstract) y el vocabulario controlado de las bases de datos consultadas (Leblanc V, Hamroun A, Bentegeac R, Le Guellec B, Lenain R, Chazard E. Added Value of Medical Subject Headings Terms in Search Strategies of Systematic Reviews: Comparative Study. J Med Internet Res. 2024 Nov 19;26:e53781. doi: 10.2196/53781.).
Debemos hacer balance entre la precisión y exhaustividad pero teniendo en cuenta que el objetivo de una búsqueda para una RS es identificar todos los estudios pertinentes (maximizar la sensibilidad pero con una precisión razonable). Una de las cuestiones más complicadas es cuando dar por finalizada la búsqueda. Una de las cuestiones más complicadas es cuando dar por finalizada la búsqueda.
Representación visual de precisión y sensibilidad al realizar una búsqueda de literatura de una revisión sistemática. Modificada y traducida de: Kumar V, Barik S, Raj V, Varikasuvu SR. Precision and Sensitivity: A Surrogate for Quality of Literature Search in Systematic Reviews. Clin Spine Surg. 2025;38(1):34-6.
Salvador-Oliván y cols., encontraron que, de las estrategias de búsqueda, el 92,7% contenían algún tipo de error. Para facilitar su presentación, los errores se agruparon en 2 categorías: los que afectan al recuerdo y los que no, siendo más frecuentes los primeros (78,1%) que los segundos (59,9%). La tabla siguiente presenta la frecuencia de los distintos tipos de errores.
Errores más comunes en las búsquedas en revisiones sistemáticas. Fuente: Salvador-Oliván JA, Marco-Cuenca G, Arquero-Avilés R. Errors in search strategies used in systematic reviews and their effects on information retrieval. J Med Libr Assoc. 2019 Apr;107(2):210-221. doi: 10.5195/jmla.2019.567.
Más recientemente, Rethlefsen y cols. encontraron que el 56.0% (163/291) de todas las búsquedas de bases de datos contenía al menos un error (Rethlefsen ML, Brigham TJ, Price C, Moher D, Bouter LM, Kirkham JJ, Schroter S, Zeegers MP. Systematic review search strategies are poorly reported and not reproducible: a cross-sectional metaresearch study. J Clin Epidemiol. 2024 Feb;166:111229. doi: 10.1016/j.jclinepi.2023.111229.).
Son relativamente fácil de tener errores con palabras mal escritas (3,8%) y errores en la sintaxis del sistema que no se encuentran fácilmente mediante la revisión ortográfica.
Es frecuente cometer errores en la aplicación de operadores booleanos (por ejemplo, OR puede haber sido sustituido involuntariamente por AND (o viceversa), o AND puede haberse utilizado para vincular frases o palabras (por ejemplo, como una conjunción) en lugar de como un operador booleano) y, más a menudo, olvidar usarlos son comunes. La mayoría de las bases de datos asumirán un AND cuando falte un operador, lo que reducirá en gran medida la sensibilidad y la precisión de su búsqueda. Por otro lado, algunas plataformas de búsqueda ignora los operadores booleanos cuando se escriben en minúscula aplicando el operador AND automáticamente al ser el operador por defecto. Esto ocurre en PubMed por lo que es recomendable escribir los operadores booleanos siempre en mayúscula.
Otro error común es la falta de precisión en la combinación con los operadores booleanos de los números de línea correcta. Por eso es muy recomendable verificar cada número de línea y combinaciones de números de línea para asegurarse de que la lógica de búsqueda se implementó correctamente.
Para intentar paliar estos errores de ejecución, es recomendable revisar la búsqueda y asegurarse de que el uso del anidamiento entre paréntesis sea lógico y se haya aplicado correctamente. También hay que tener en cuenta si el uso de un operador de proximidad o adyacencia en lugar de AND podría aumentar la precisión. Si se utilizan operadores de proximidad, considere si la amplitud elegida es demasiado reducida para capturar todos los casos esperados de los términos de búsqueda, que pueden variar dependiendo de si la base de datos en la que se busca reconoce o no palabras vacías. Considere si la amplitud es demasiado extensa. Y si se incluyen límites (por ejemplo, humanos o población de ancianos), debemos asegurarnos de que se haya utilizado la construcción adecuada.
De las diferentes formas de construcción de la estrategia de búsqueda, recomiendo la búsqueda por bloques, es decir, una línea por cada concepto de búsqueda partiendo de nuestra pregunta estructurada (PICOs) para intentar minimizar los errores antes descritos. De esta forma, la búsqueda se corresponderá con el marco de nuestra pregunta del que partimos en nuestra revisión. (ver entrada «Cómo estructurar la estrategia de búsqueda para revisiones sistemáticas: tres enfoques diferentes pero complementarios»).
Los términos de texto libre se utilizan normalmente para cubrir los encabezamientos de materia que faltan en la base de datos, recuperar registros no indizados o mal indizados. Debemos considerar los elementos del uso del texto libre, como demasiado restringido o demasiado amplio, la relevancia de los términos y si se han incluido sinónimos o antónimos.
Con respecto al uso de descriptores o encabezamientos de materia, hemos de comprobar si faltan encabezamientos o si son incorrectos los que utilizamos en nuestra estrategia, analizar la relevancia/irrelevancia de los términos y el uso correcto de la búsqueda ampliada para incluir términos relevantes más específicos.
Debemos considerar que el uso de subencabezamientos flotantes que en la mayoría de los casos son preferibles al uso de subencabezamientos ligados a encabezados de materias específicas.
Adaptación entre bases de datos y plataformas
Una vez hemos realizado la búsqueda en una base de datos debemos trasladar la estrategia a la siguiente base de datos. Esto significa que el vocabulario controlado, los términos del lenguaje natural y todas las demás etiquetas y operadores de campo utilizados deben ser lo más similar posible.
Deficiencias en la documentación de las estrategias de búsqueda de evidencia
Las búsquedas de revisión sistemática deben ser reproducibles, pero la mayoría no lo son. Rethlefsen y cols. encontraron que solo el 1% de las revisiones sistemáticas eran completamente reproducibles para todas las búsquedas de bases de datos. Además, las búsquedas de revisión sistemática siguen informándose mal. La gran mayoría de las revisiones sistemáticas (91%) ni siquiera proporciona suficientes detalles para identificar las bases de datos/plataformas utilizadas para todas las búsquedas de bases de datos (Rethlefsen ML, Brigham TJ, Price C, Moher D, Bouter LM, Kirkham JJ, Schroter S, Zeegers MP. Systematic review search strategies are poorly reported and not reproducible: a cross-sectional metaresearch study. J Clin Epidemiol. 2024 Feb;166:111229. doi: 10.1016/j.jclinepi.2023.111229.).
Recomendaciones para mejorar las estrategias de búsqueda en revisiones sistemáticas
Para intentar minimizar los errores en la búsqueda en revisiones sistemáticas, es recomendable que un segundo bibliotecario haga la revisión por pares de la búsqueda utilizando la herramienta PRESS (Peer Review of Electronic Search Strategies (McGowan J, Sampson M, Salzwedel DM, Cogo E, Foerster V, Lefebvre C. PRESS Peer Review of Electronic Search Strategies: 2015 Guideline Statement. J Clin Epidemiol. 2016 Jul;75:40-6. doi: 10.1016/j.jclinepi.2016.01.021. PMID: 27005575.) justo antes de finalizar el protocolo y antes de hacer las búsquedas definitivas de la revisión.
Y por último, para la mejora de las estrategias de búsqueda y su informe transparente es necesario implicar a los bibliotecarios, los equipos de revisión sistemática, los revisores por pares y los editores de revistas.