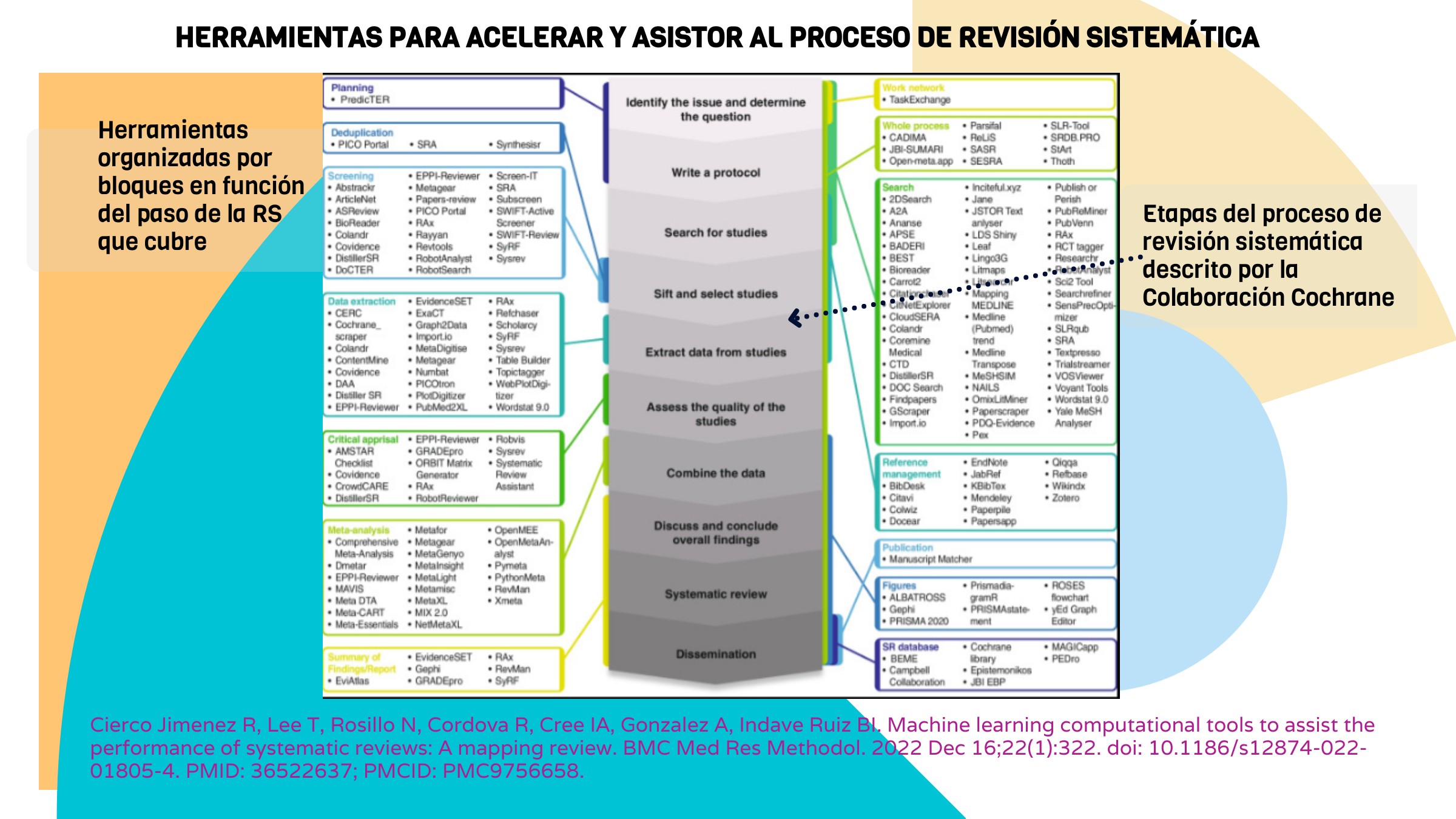
Hasta ahora, diseñar una estrategia de búsqueda sólida, localizar estudios relevantes y manejar cientos de referencias era un trabajo artesanal, intensivo en tiempo y dependiente por completo de la experiencia humana. Sin embargo, la integración de modelos de lenguaje generativo en los procesos de revisión sistemática está modificando de manera sustancial la fase de búsqueda y recuperación de información.
La clave está en entender qué puede hacer cada uno y cómo combinar sus fortalezas para obtener búsquedas más robustas, eficientes y reproducibles en un contexto donde la calidad de la evidencia importa más que nunca.
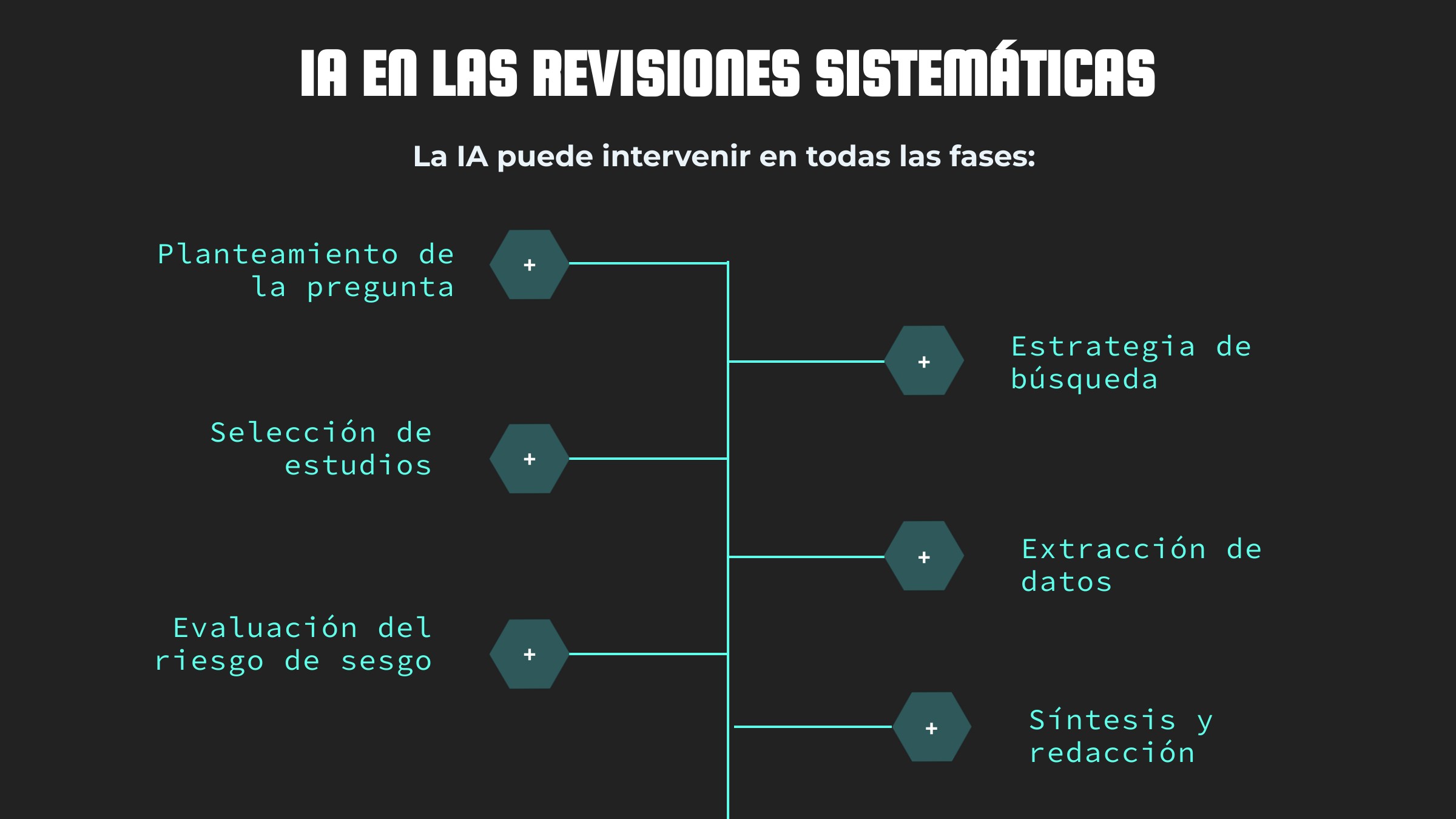
Tareas en las que puede intervenir la IA
La aportación de la IA no reside únicamente en la aceleración de tareas, sino en la capacidad de ampliar, diversificar y estructurar el acceso a la literatura científica, amplificando los procedimientos manuales.
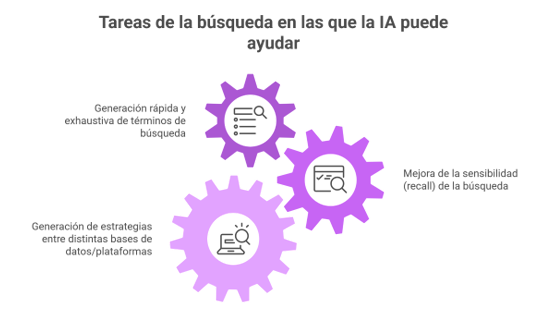
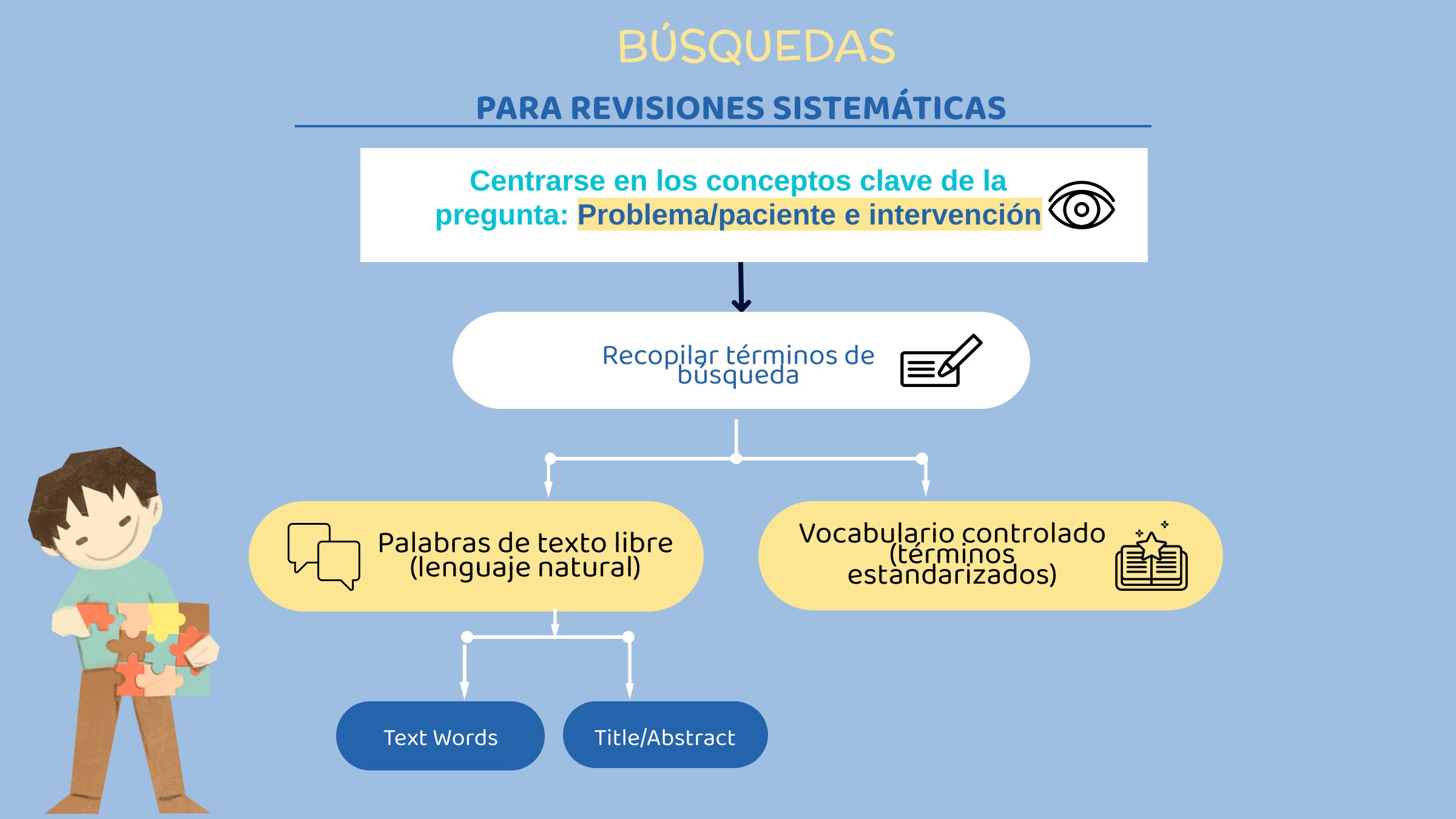
- Generación rápida y exhaustiva de términos de búsqueda. Los modelos de IA generativa son capaces de recopilar términos de miles de textos y, a partir de ahí, sugieren sinónimos, acrónimos y variantes de un mismo concepto. En otras palabras, ayudan a descubrir términos relevantes que, de otro modo, podrían pasarse por alto. Esta capacidad resulta especialmente útil en áreas emergentes o interdisciplinarias, donde la terminología aún no está normalizada y la literatura se dispersa en múltiples dominios temáticos.
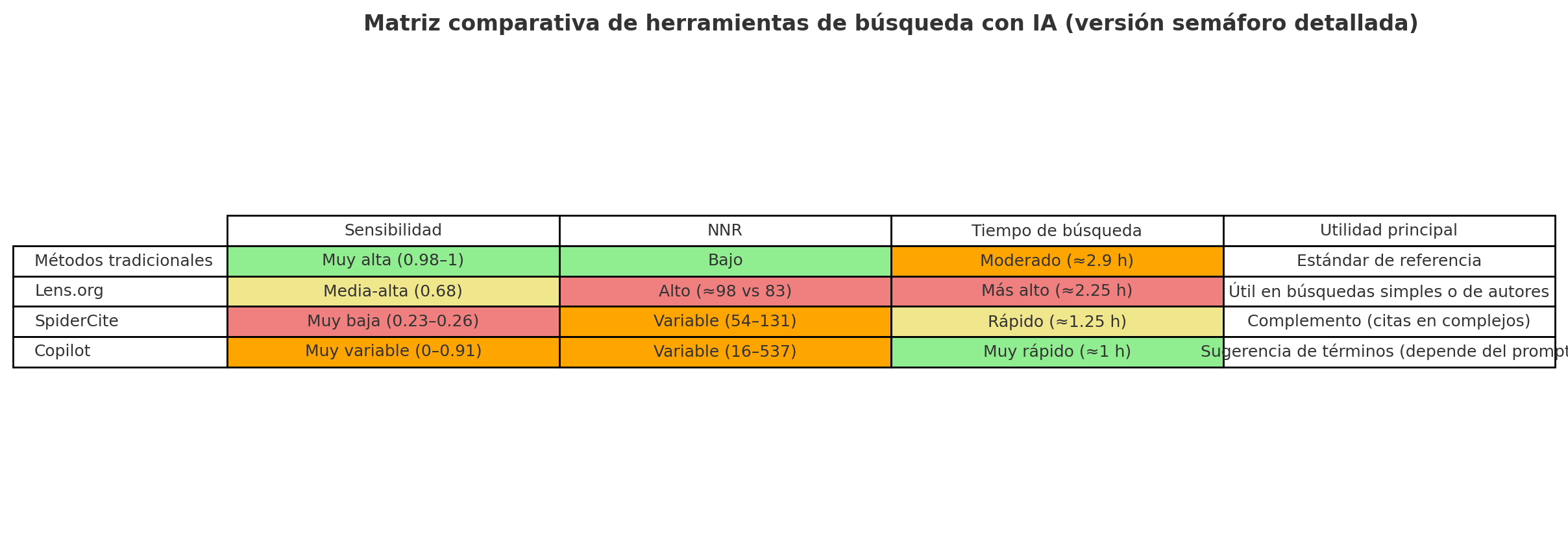
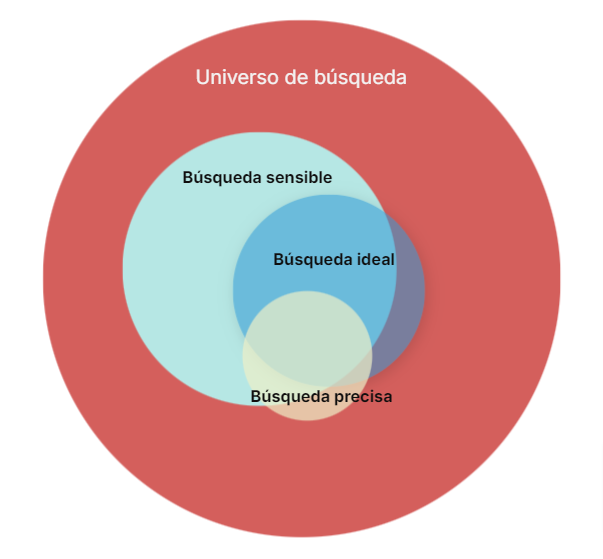
- Aumento de la sensibilidad/exhaustividad (recall) de la búsqueda. Estas herramientas son capaces de producir una primera estrategia de búsqueda con elevada sensibilidad, es decir, muy amplia, recuperando muchísimos resultados. Es verdad que luego hay que limpiarlos y depurarlos, pero esa “primera cosecha” sirve como una base sólida sobre la que seguir afinando la estrategia, añadir filtros y ajustar los términos. En este sentido, la IA funciona como un acelerador: te ayuda a arrancar rápido con un punto de partida fuerte, aunque siempre hace falta la mirada experta del bibliotecario para asegurar que todo tenga sentido y calidad.
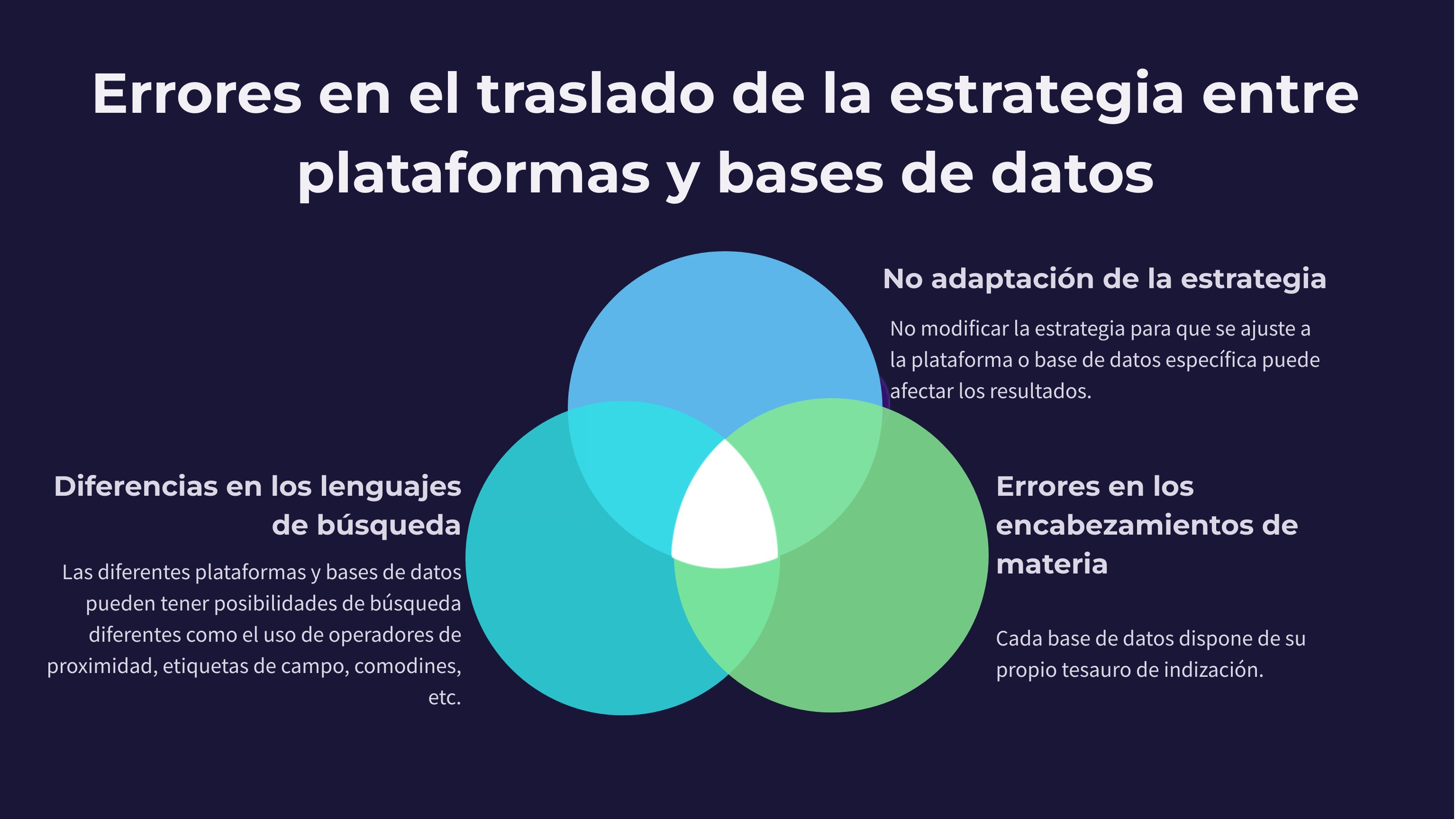
- Generación de búsquedas booleanas para distintas bases de datos/plataformas. Uno de los avances más visibles es la capacidad de la IA para traducir una estrategia conceptual en consultas operativas adaptadas a la sintaxis de cada proveedor: Ovid MEDLINE, Embase.com, Scopus, Web of Science, CINAHL (EBSCO, Ovid, …), PsycINFO (Proquest, EBSCO, …), entre otros. Esto incluye la aplicación correcta de campos de búsqueda, operadores de proximidad, truncamientos, tesauros controlados y peculiaridades funcionales de cada motor. Esta precisión reduce errores, evita pérdidas de sensibilidad y mejora la reproducibilidad del proceso.
Ventajas/Oportunidades del uso de la IA
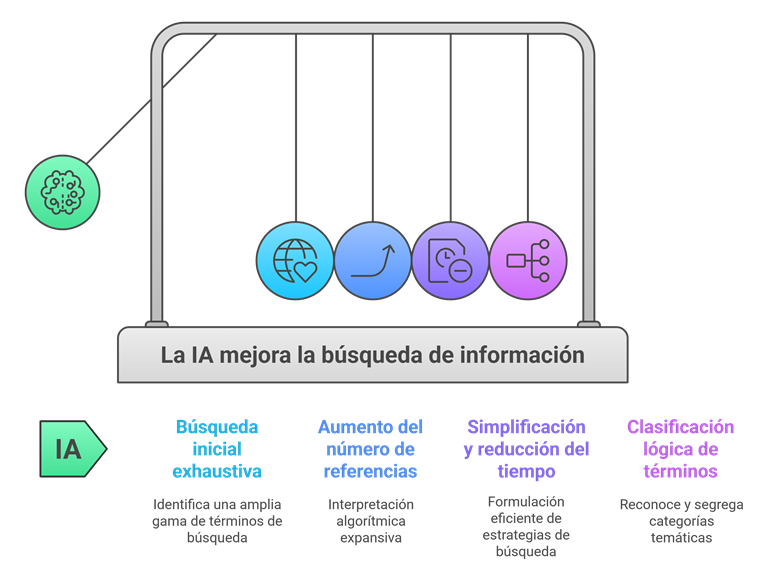
- Fase de búsqueda inicial más exhaustiva: La IA puede generar en pocos segundos un abanico enorme de términos, sinónimos y palabras clave relacionadas con un tema. Esto resulta especialmente útil cuando nos enfrentamos a un campo nuevo o del que sabemos poco: la herramienta propone conceptos que quizá no habríamos considerado y evita que la estrategia de búsqueda se quede corta.
- Más referencias desde el principio: Las herramientas de IA suelen recuperar mucho más. Su forma de interpretar las palabras clave es más amplia que la nuestra, lo que se traduce en un volumen mayor de resultados. Luego tocará depurarlos, sí, pero arrancar con una red más grande ayuda a no dejar estudios relevantes fuera.
- Menos tiempo perdido al adaptar estrategias entre bases de datos: Pasar una estrategia de búsqueda de MEDLINE (PubMed u OVID) a Embase.com, Scopus o WoS es un trabajo pesado, repetitivo y lleno de pequeños detalles que es fácil olvidar. La IA puede hacerlo automáticamente, respetando sintaxis, operadores booleanos y campos correctos en cada plataforma. En la práctica, esto supone menos errores y muchas horas ahorradas.
- Orden y lógica en los términos: Además de reunir términos útiles, la IA es capaz de agruparlos por categorías o temas. No solo te dice qué palabras usar, sino que te ayuda a entender cómo se relacionan entre sí, lo que facilita estructurar la búsqueda con sentido.
Inconvenientes y retos del uso de IA en las revisiones sistemáticas
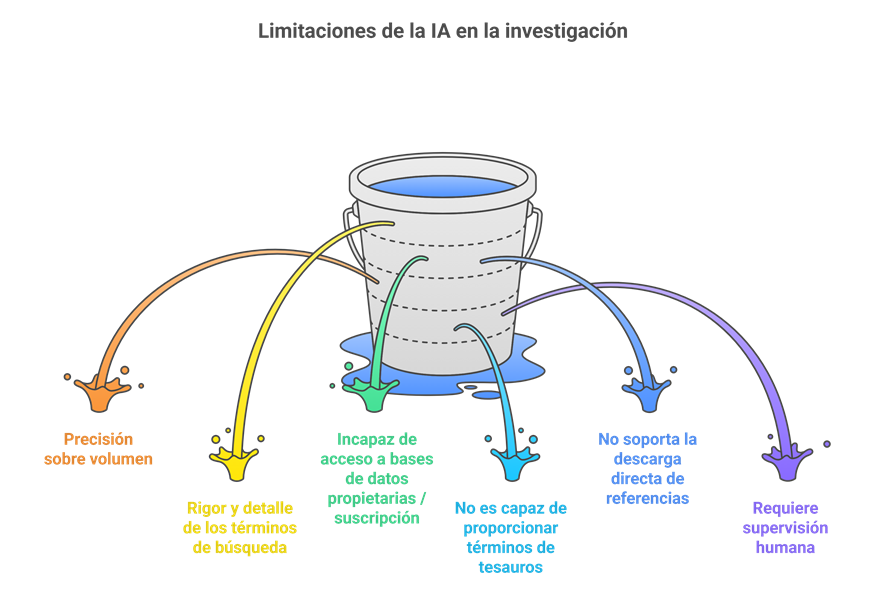
- Mucho volumen, poca precisión: Que la IA recupere cientos o miles de referencias puede parecer una ventaja, pero tiene trampa: no distingue bien lo relevante de lo accesorio. Esto obliga a dedicar tiempo extra a revisar y descartar estudios que no encajan con la pregunta de investigación. En cambio, una estrategia elaborada por un bibliotecario suele ser más ajustada desde el principio, porque está pensada para responder a criterios concretos y no para abarcar “todo lo que pueda sonar parecido”.
- La experiencia humana sigue siendo irremplazable: La IA propone muchos términos, sí, pero no sabe cuándo un matiz importa. Afinar la estrategia de búsqueda, elegir el descriptor correcto o decidir si un término aporta ruido o información útil sigue siendo territorio humano. Las listas generadas por la IA necesitan ser revisadas, depuradas y enriquecidas por alguien que entienda el contexto, las particularidades del tema y las implicaciones metodológicas.
- Limitaciones de acceso a bases de datos suscritas: Hoy por hoy, la mayoría de modelos de IA no pueden entrar en bases de datos científicas de pago. Esto significa que no pueden comprobar en tiempo real qué términos están indexados, qué descriptores existen o cómo se estructura un determinado tesauro especializado.
- No puede moverse por tesauros especializados: Al no tener acceso a bases como EMBASE, CINAHL o PsycINFO, la IA no es capaz de navegar por sus tesauros y proponer descriptores correctos. Este es un punto crítico porque las estrategias de búsqueda más sólidas combinan términos libres con términos controlados, y esa fineza todavía no está al alcance de las herramientas generativas.
- No descarga ni extrae referencias: Otra limitación importante es que la IA no puede descargar los resultados de la búsqueda ni gestionarlos en un gestor bibliográfico. Sigue siendo necesario pasar por las plataformas originales para obtener los registros y preparar la deduplicación o el cribado.
- Siempre necesita supervisión: El uso de IA no elimina la figura del bibliotecario experto ni del equipo de revisión. Más bien cambia su papel: deja de ser quien hace cada paso manualmente para convertirse en quien valida, corrige y toma decisiones informadas. Sin esa supervisión, la IA puede generar estrategias amplias, pero no necesariamente adecuadas.

Un modelo sinérgico: IA + bibliotecario
El futuro inmediato no pasa por elegir entre inteligencia artificial o bibliotecario especializado, sino por combinarlos teniendo en cuenta las fortalezas y limitaciones de cada uno de ellos. Cada uno aporta algo diferente y, cuando trabajan juntos, el proceso de búsqueda y revisión gana en velocidad, alcance y rigor.
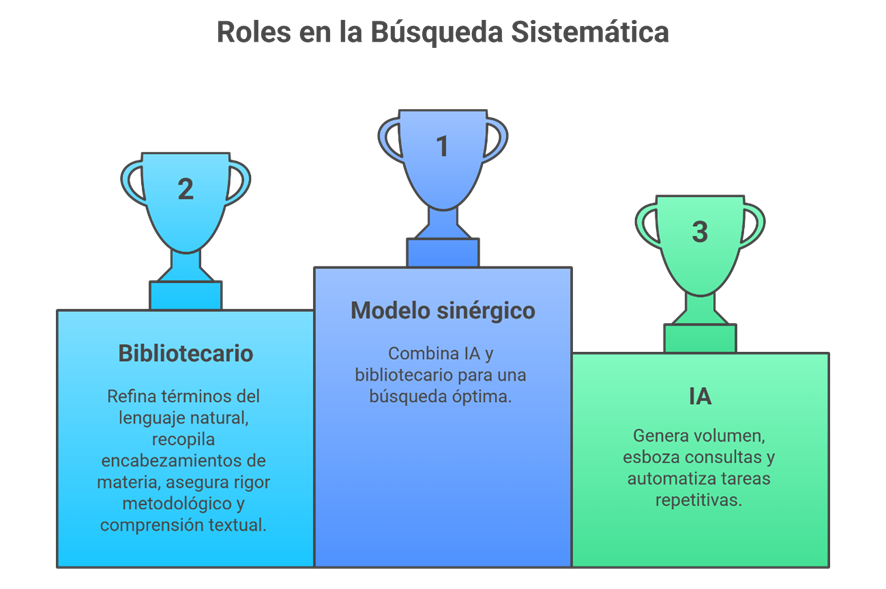
¿Cuál sería el rol de la IA?
La IA es especialmente útil en las primeras fases del trabajo. Su fortaleza está en generar cantidad: propone términos, sugiere combinaciones, construye borradores de estrategias de búsqueda y automatiza tareas tediosas como adaptar consultas entre plataformas o expandir sinónimos. Es rápida y eficiente para mover grandes volúmenes de información.
¿Qué aporta el bibliotecario?
El bibliotecario, por su parte, aporta calidad. No solo afina la terminología y valida los conceptos relevantes, sino que es quien domina el uso de tesauros, entiende la lógica de indexación de cada base de datos y detecta inconsistencias que la IA no ve. Además, garantiza el rigor metodológico: sabe cuándo un término es demasiado amplio, cuándo un operador puede distorsionar la pregunta de investigación y cómo documentar correctamente una estrategia reproducible.
En resumen (recuerda las pautas RAISE) …
- La IA debe usarse como compañera de los humanos, no como sustituta.
- Tú eres, en última instancia, responsable de su síntesis de la evidencia, incluida la decisión de usar IA y de garantizar la adhesión a las normas legales y éticas.
- Usa la IA siempre que no comprometas el rigor metodológico ni la integridad de la síntesis.
- Debes de informar de forma completa y trasparente del uso de cualquier IA que emita o sugiera juicios.