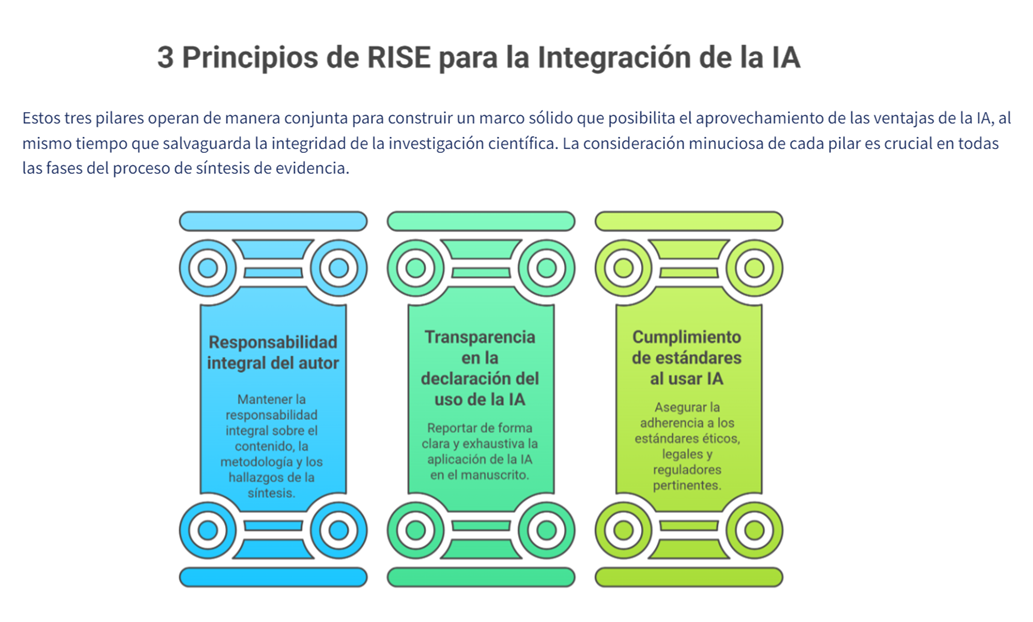
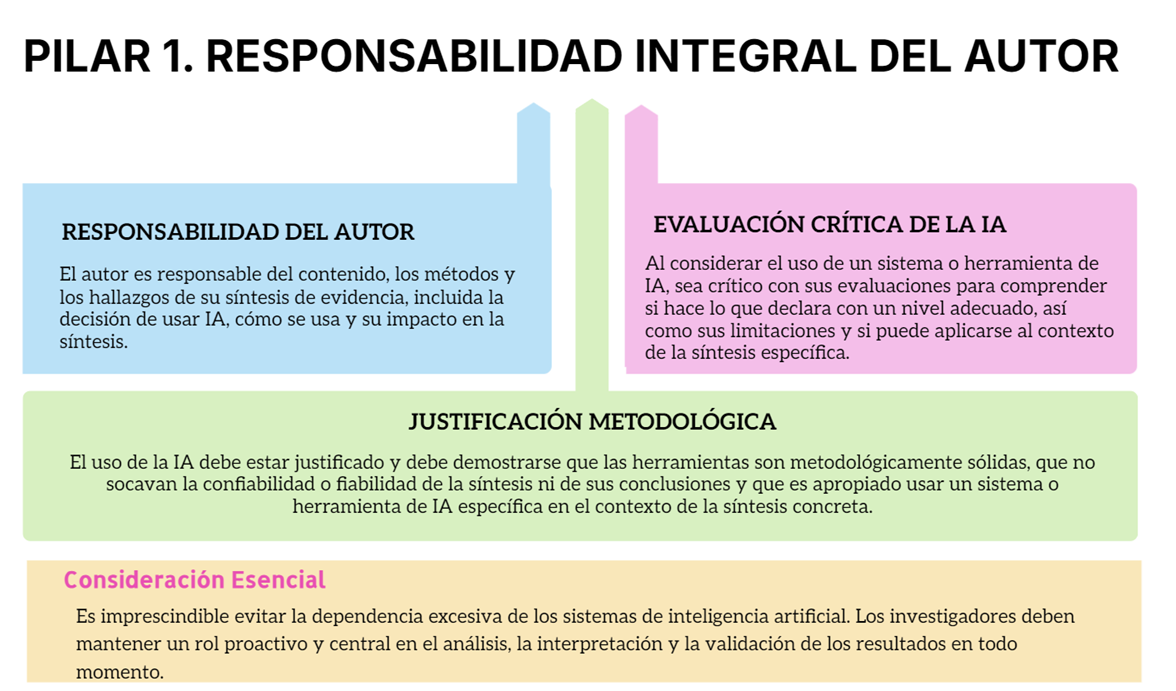
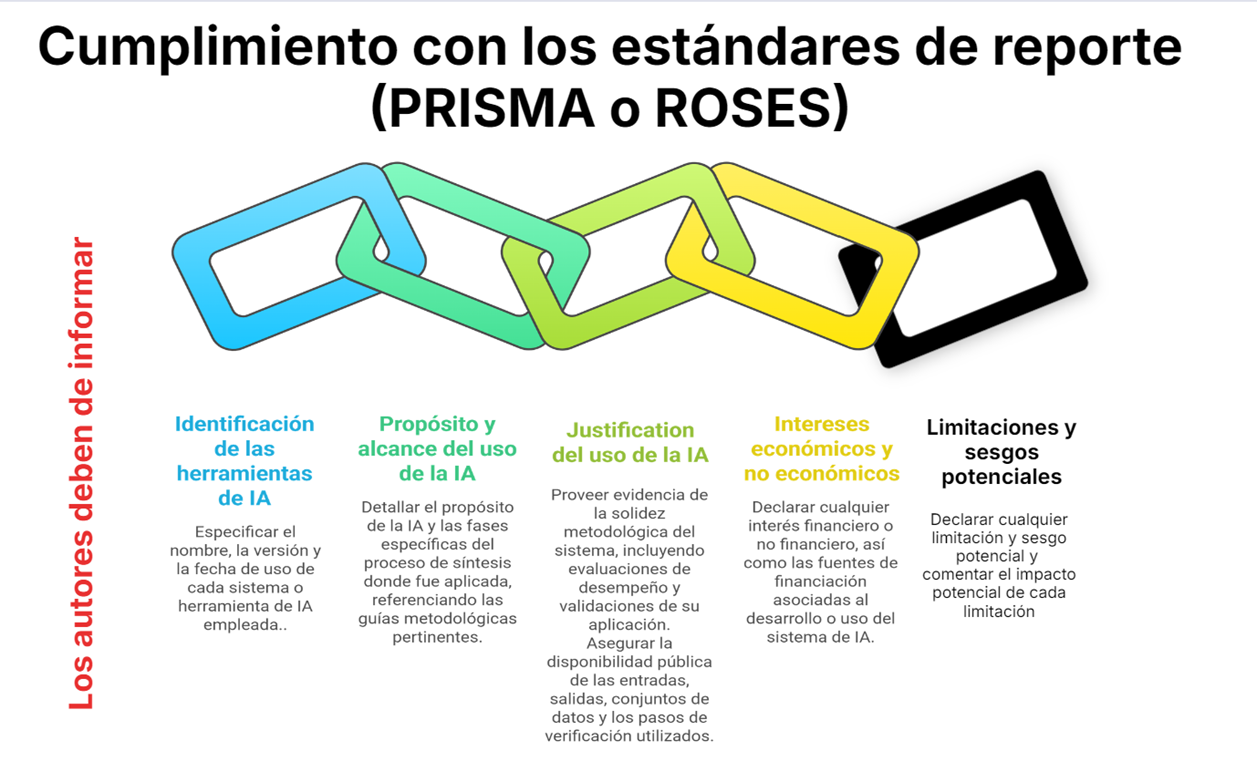
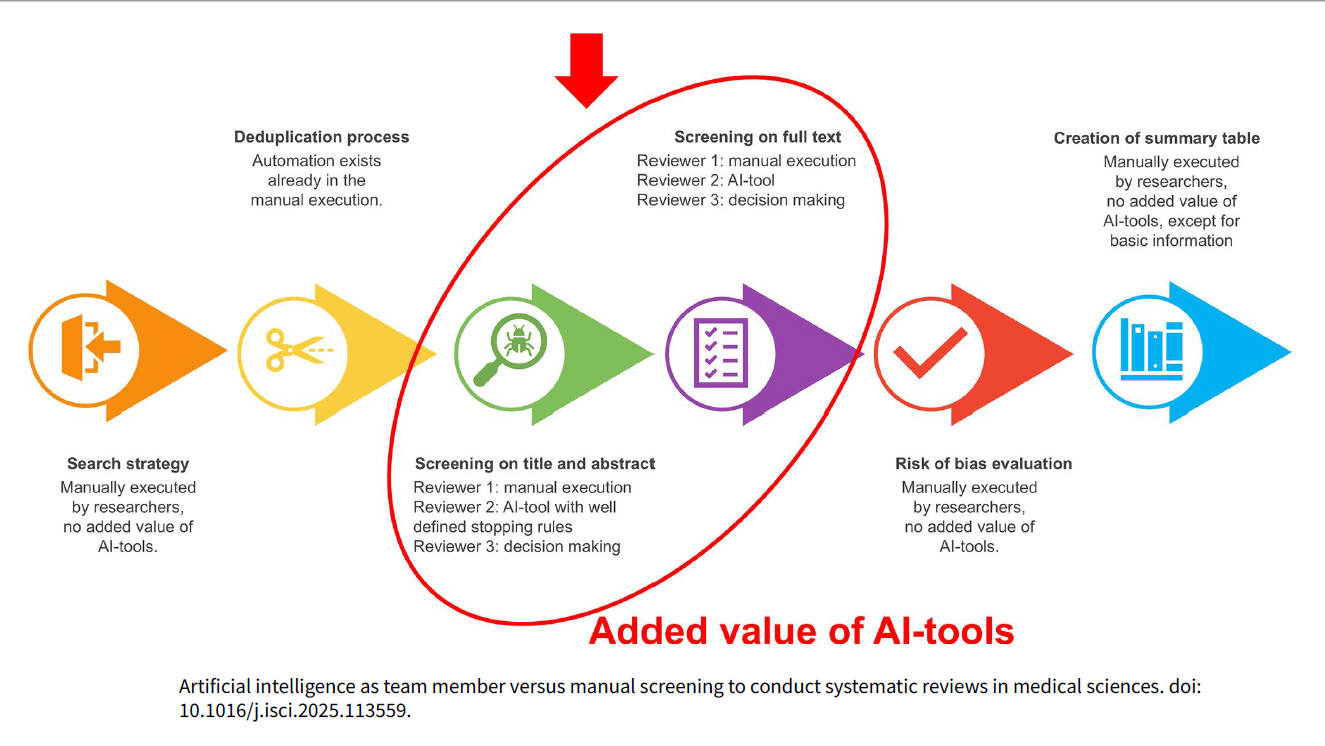
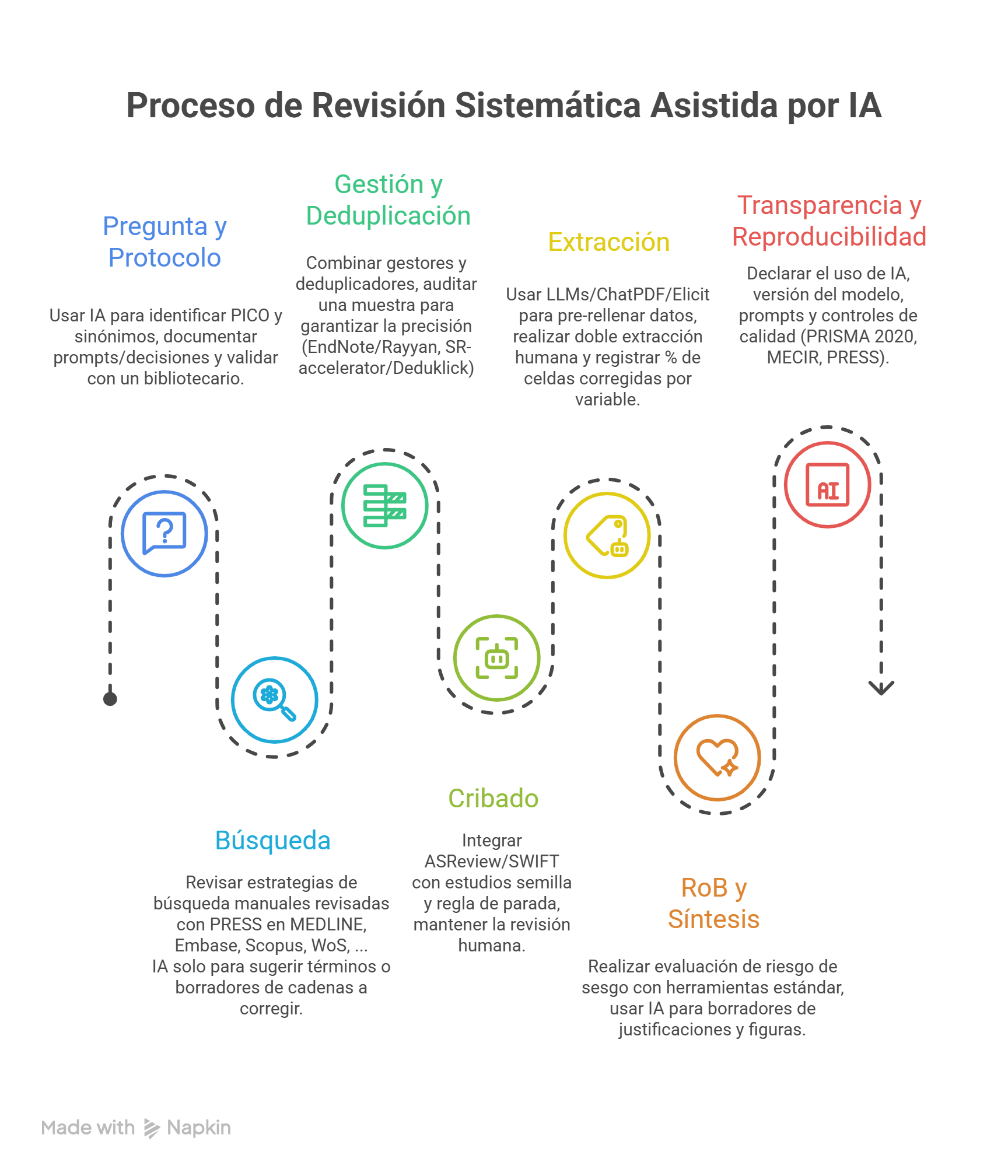
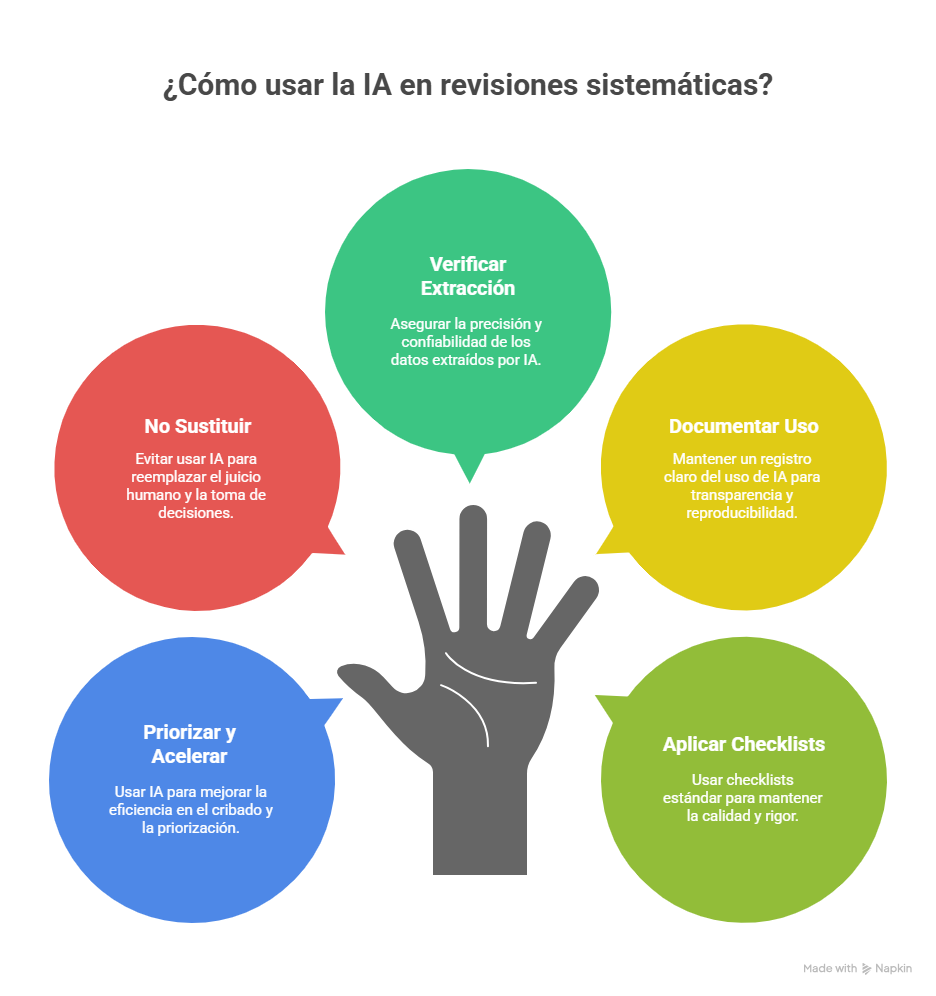
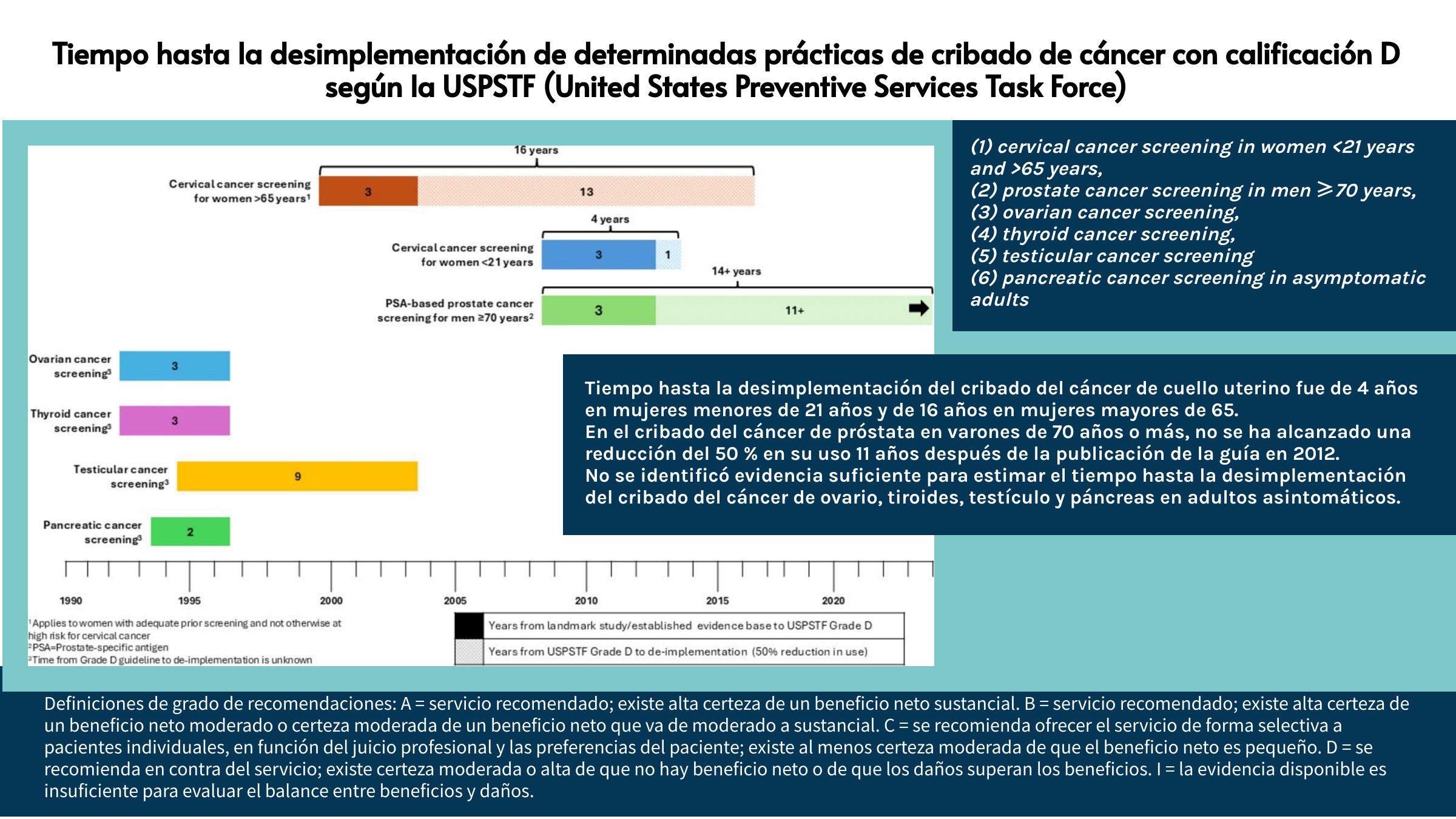
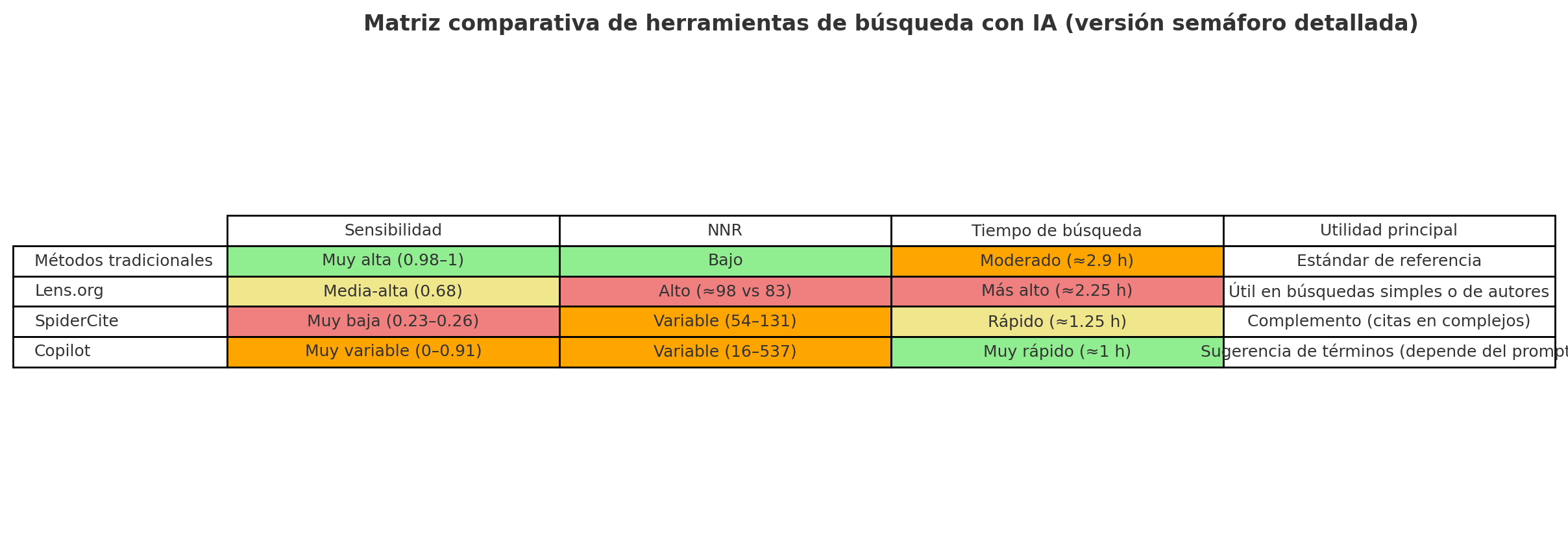
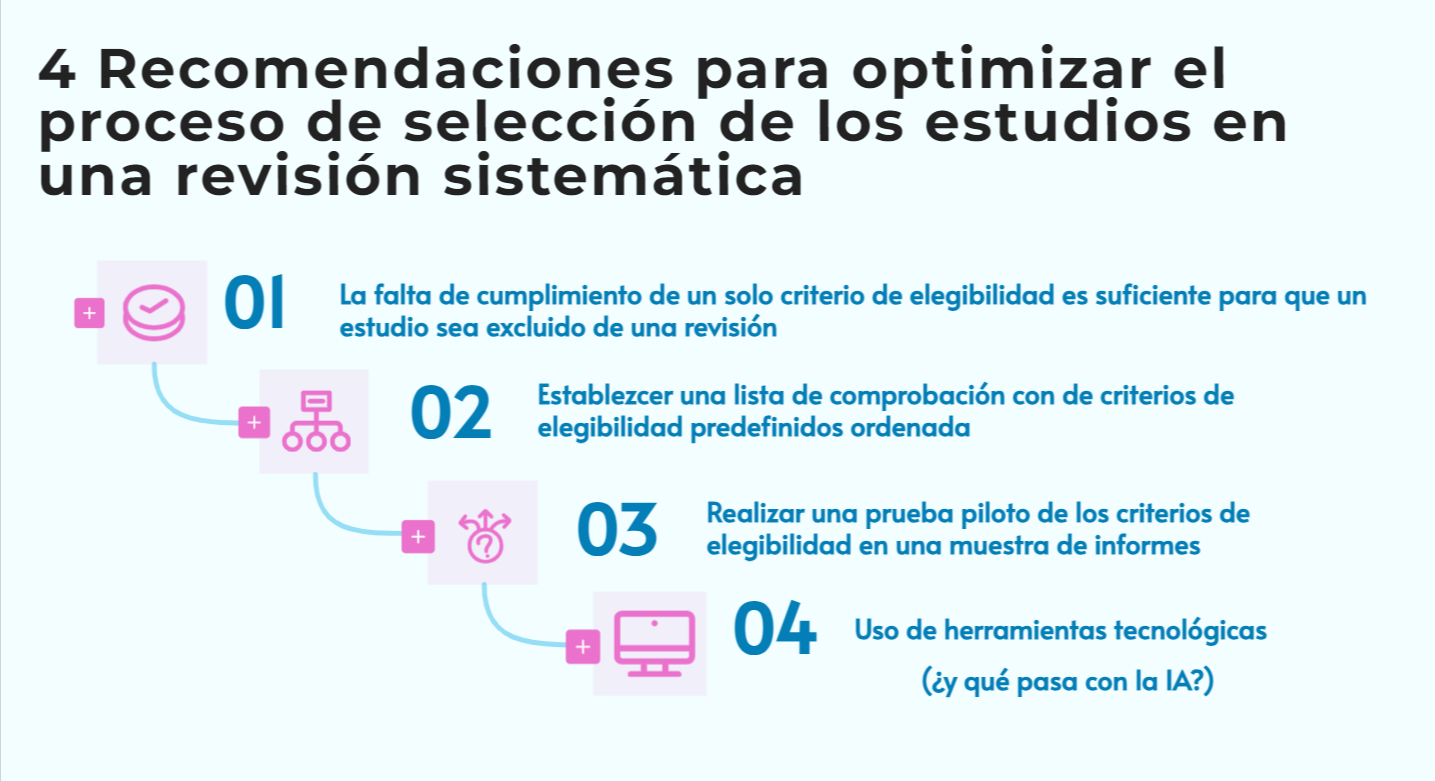
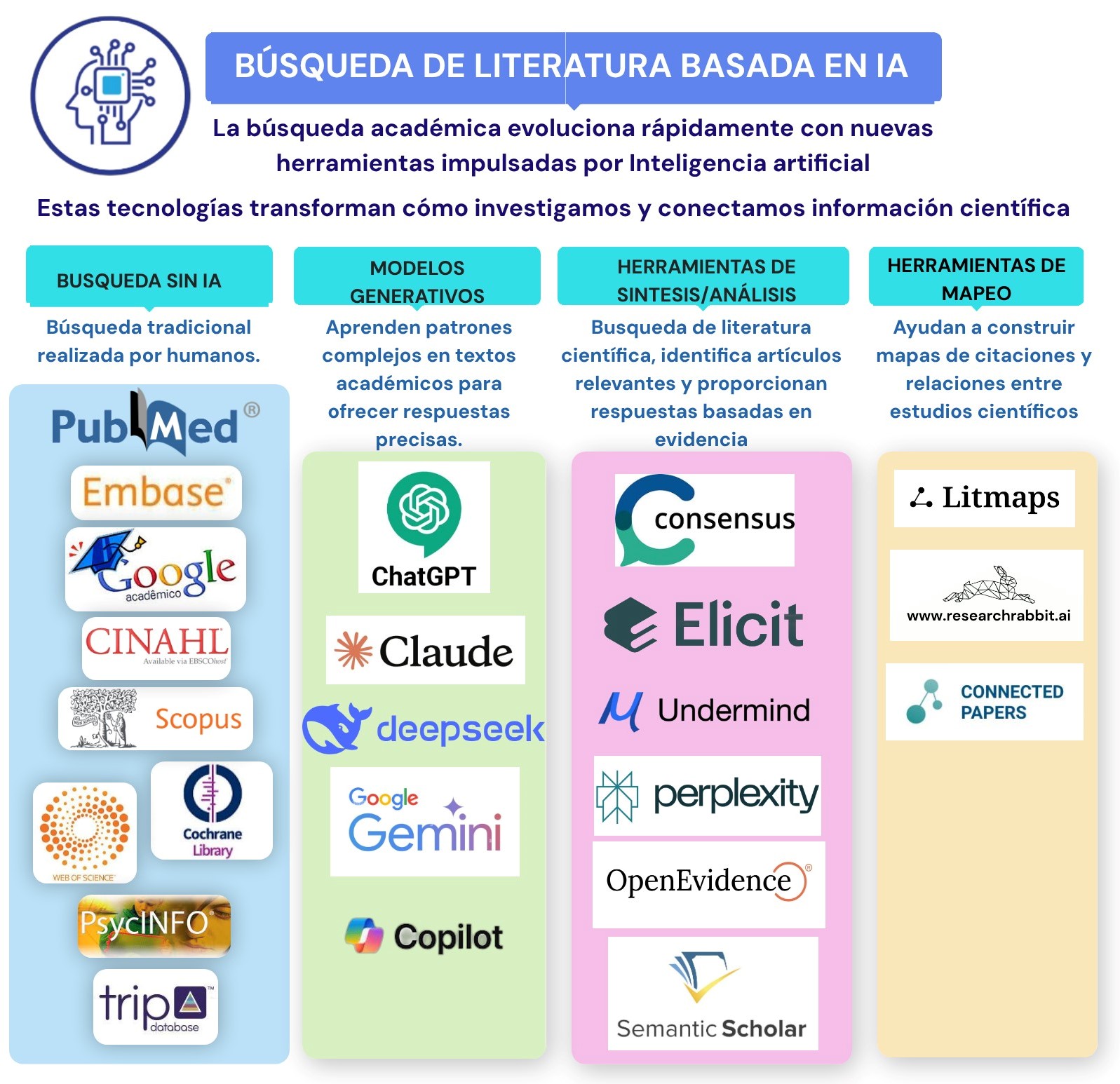
Durante años, Rayyan ha sido especialmente sólido en el cribado por título/resumen, pero muchos equipos (y, en particular, quienes coordinamos revisiones con volúmenes altos) nos encontrábamos con dificultades claras cuando el proyecto avanzaba hacia el texto completo y la gestión documental.
Las limitaciones de Rayyan
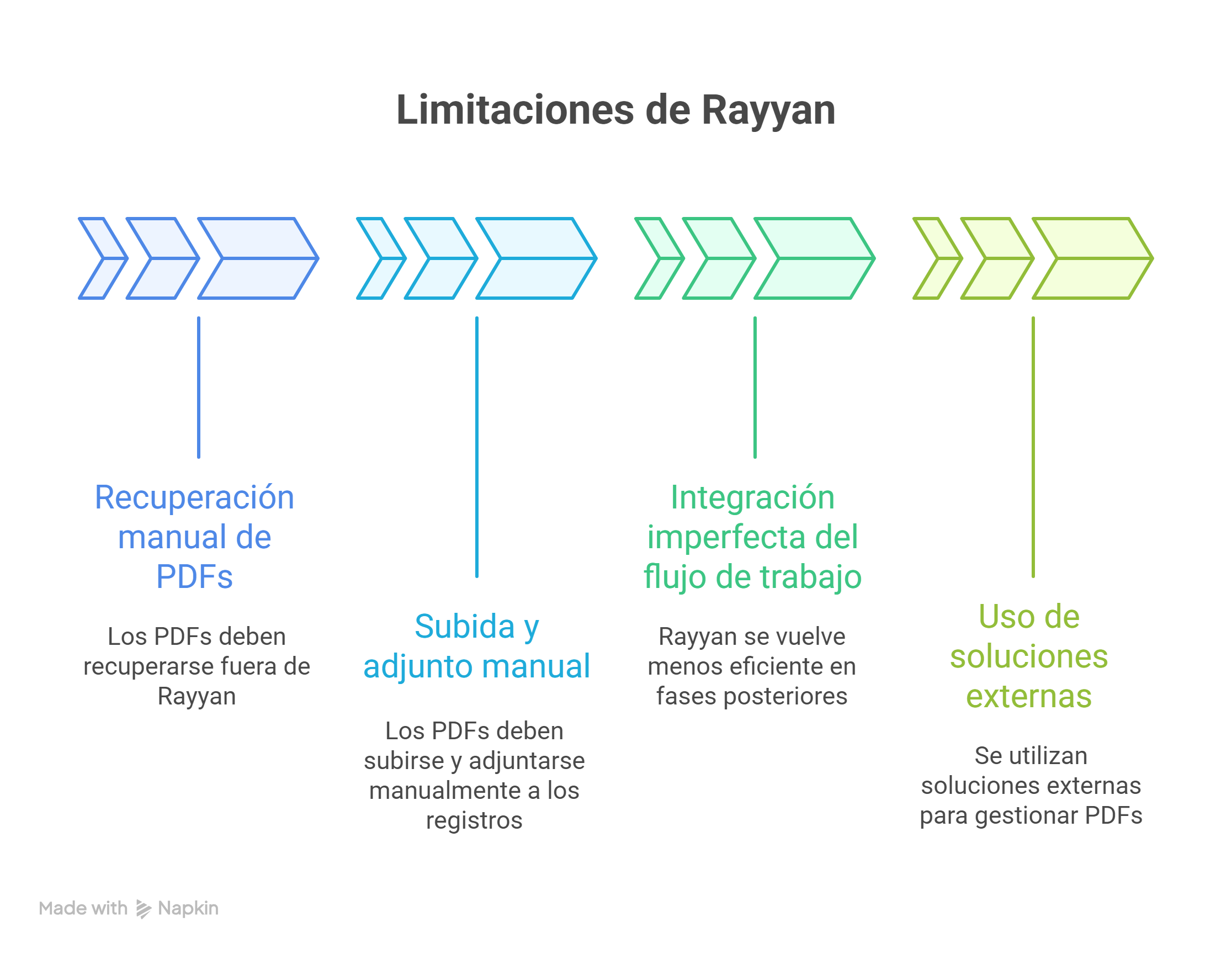
Históricamente, Rayyan se diseñó como herramienta de cribado y, aunque ha ido incorporando módulos posteriores, en la práctica cotidiana se repetían algunos problemas:
- Gestión manual de textos completos (PDF): Los PDFs debían recuperarse fuera de Rayyan. Después, había que subirlos y adjuntarlos manualmente a cada registro, uno a uno.
- Integración imperfecta del flujo de trabajo: Rayyan resultaba muy eficiente en el primer cribado, pero el proceso tendía a volverse más “pesado” en fases posteriores. Era frecuente recurrir a soluciones externas (carpetas compartidas, gestores bibliográficos paralelos, etc.) para poder trabajar con muchos PDFs de forma operativa.
La novedad: “Mi Biblioteca” (My Library)
Rayyan ha introducido Mi Biblioteca como un espacio estable, reutilizable y conectado a las revisiones, diseñado para centralizar archivos y reducir trabajo manual, especialmente en el cribado a texto completo.
En términos prácticos, “Mi Biblioteca” funciona como una biblioteca personal en la nube dentro de Rayyan, desde la que puedes organizar, conservar y reutilizar materiales (referencias, PDFs y otros archivos) en distintos proyectos.
Beneficios de «My Library»
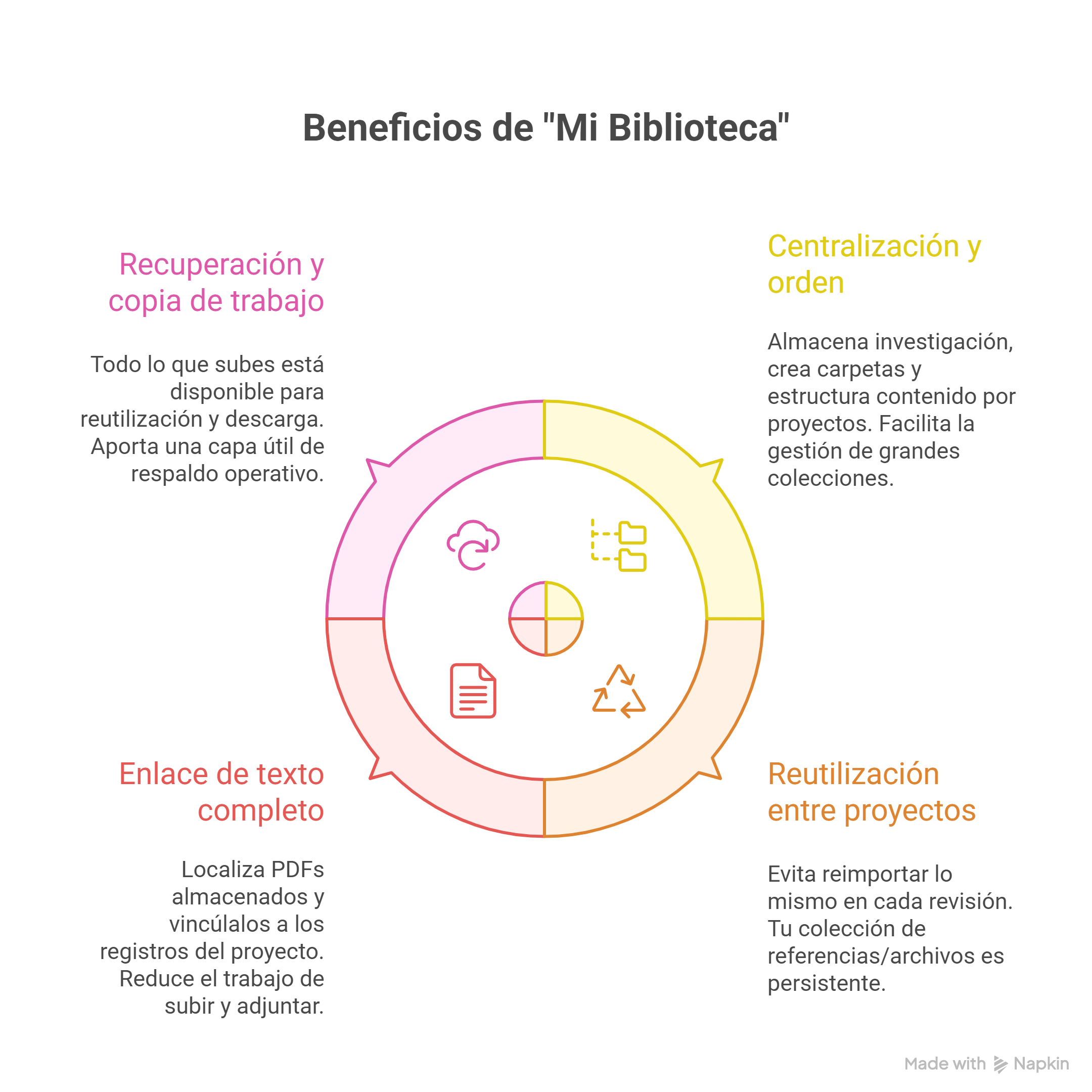
1) Centralización y orden (por fin, “un sitio” para todo)
- Permite almacenar una colección propia de investigación, con referencias y textos completos.
- Puedes crear carpetas y estructurar el contenido por proyectos, temas o etapas.
- Facilita la gestión de colecciones grandes con una lógica de “repositorio” (custodia y reutilización, no solo importación puntual).
2) Reutilización real entre proyectos
Una idea clave es evitar el “déjà vu” de reimportar lo mismo en cada revisión: “Mi Biblioteca” está pensada para que tu colección de referencias/archivos sea persistente y puedas usar los mismos ítems en revisiones diferentes cuando lo necesites.
3) El gran cuello de botella: texto completo (PDF) y su enlace al registro
Aquí está el salto más práctico: durante la fase de cribado a texto completo, puedes localizar PDF ya almacenados en Mi Biblioteca y vincularlos a los registros del proyecto, reduciendo el trabajo de “subir y adjuntar” uno por uno desde cero en cada revisión.
4) Recuperación y “copia de trabajo”
Todo lo que subes queda disponible para su reutilización y descarga, lo que aporta una capa útil de respaldo operativo (especialmente cuando el equipo trabaja con múltiples revisiones o rotación de participantes).
Implicaciones para bibliotecas hospitalarias y equipos de revisión
- Reducir trabajo manual repetitivo.
- Mejorar la trazabilidad (dónde está cada PDF, cuándo se incorporó, a qué proyecto se vinculó).
- Disminuir dependencias de circuitos paralelos (carpetas compartidas + “doble” gestión fuera de la plataforma).
Cautelas (importantes)
- No es un sistema de obtención de texto completo: “Mi Biblioteca” no sustituye el acceso: sigue siendo imprescindible disponer de los PDFs por vías legítimas (suscripción institucional, OA, solicitud a autores, etc.).
- Qué puedes hacer con cuenta gratuita:
- Subir y organizar PDFs y archivos de referencias en Mi Biblioteca, sin límite de espacio tan solo que cada PDF no exceda 100MB, y no subir más de 10 a la vez.
- Reutilizar esas referencias en distintas revisiones.
- Buscar PDFs en Mi Biblioteca durante el cribado a texto completo y emparejarlos manualmente con las referencias.
- Qué queda restringido a planes de pago: El PDF Auto Matching (la asignación automática de PDFs a las referencias) es una funcionalidad solo de pago.

En resumen …
“Mi Biblioteca” supone una notable mejora, ya que actúa en el eslabón más frágil del flujo de trabajo en Rayyan: la gestión del texto completo y su acoplamiento al cribado. Para quienes trabajamos apoyando revisiones sistemáticas desde bibliotecas hospitalarias, este cambio puede traducirse en menos trabajo manual, más orden y más eficiencia en proyectos de alto volumen.
Más información: https://help.rayyan.ai/hc/en-us/articles/41494414324625-How-to-Use-My-Library