
La inteligencia artificial (IA)—y, en particular, los modelos de lenguaje (LLMs)—ya están ayudando a hacer revisiones sistemáticas (RS) más rápidas y manejables, pero aún no pueden reemplazar el juicio experto ni los métodos sistemáticos consolidados. A continuación resumo qué funciona, qué no, y cómo implantarlo con garantías.
Qué dice la evidencia más reciente sobre LLMs
Una revisión de alcance (n=196 informes; 37 centrados en LLMs) encontró que los LLMs ya se usan en 10 de 13 pasos de la RS (sobre todo búsqueda, selección y extracción). GPT fue el LLM más común. La mitad de los estudios calificó su uso como prometedor, un cuarto neutral y un quinto no prometedor. La búsqueda fue, con diferencia, el paso más cuestionado; en RoB la concordancia con humanos fue solo ligera a aceptable (Lieberum JL, et al. 2024).

¿Dónde aporta más (hoy) la IA?
La IA acelera y prioriza (especialmente en el cribado), pero no sustituye la búsqueda sensible, la evaluación del sesgo ni el juicio experto.
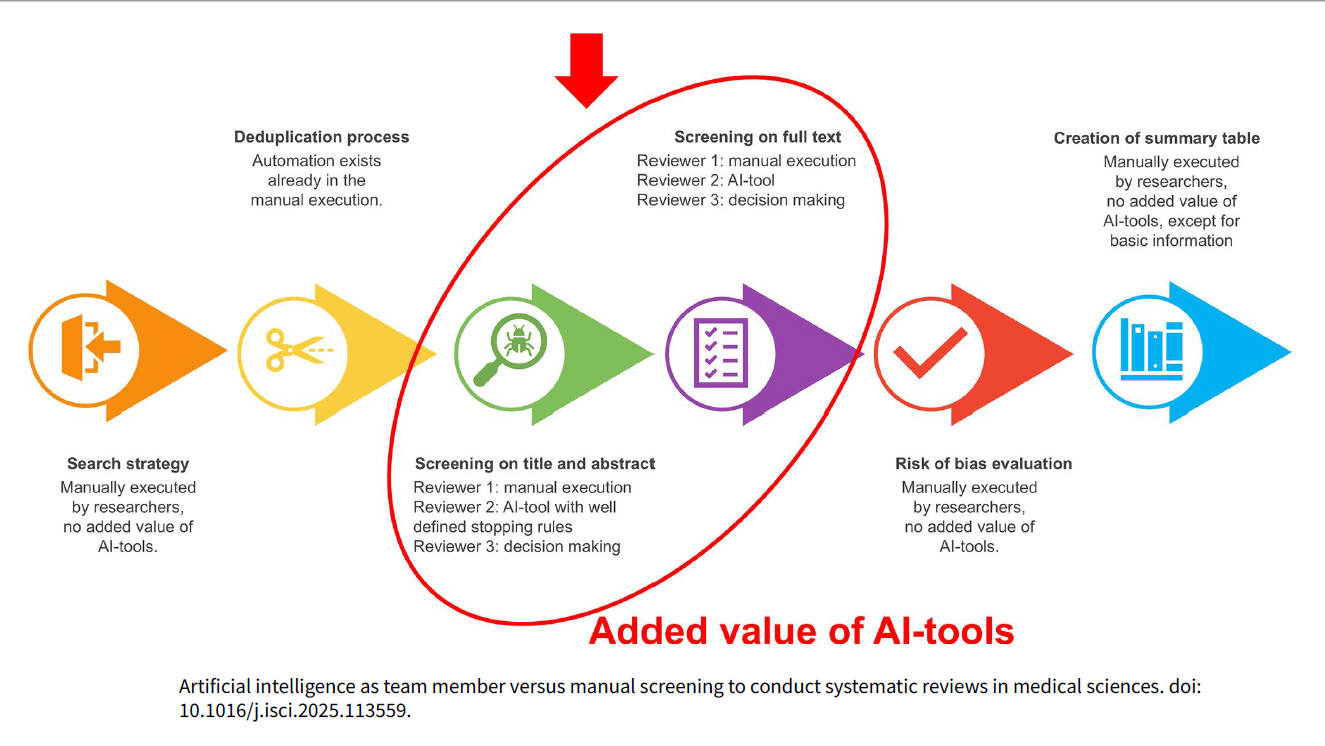
1) Cribado (títulos/resúmenes y, con matices, texto completo)
- Aprendizaje activo para priorizar lo relevante primero: Ayudar al revisor humano a reordenar los artículos para presentar primero los más relevantes (aprendizaje activo).
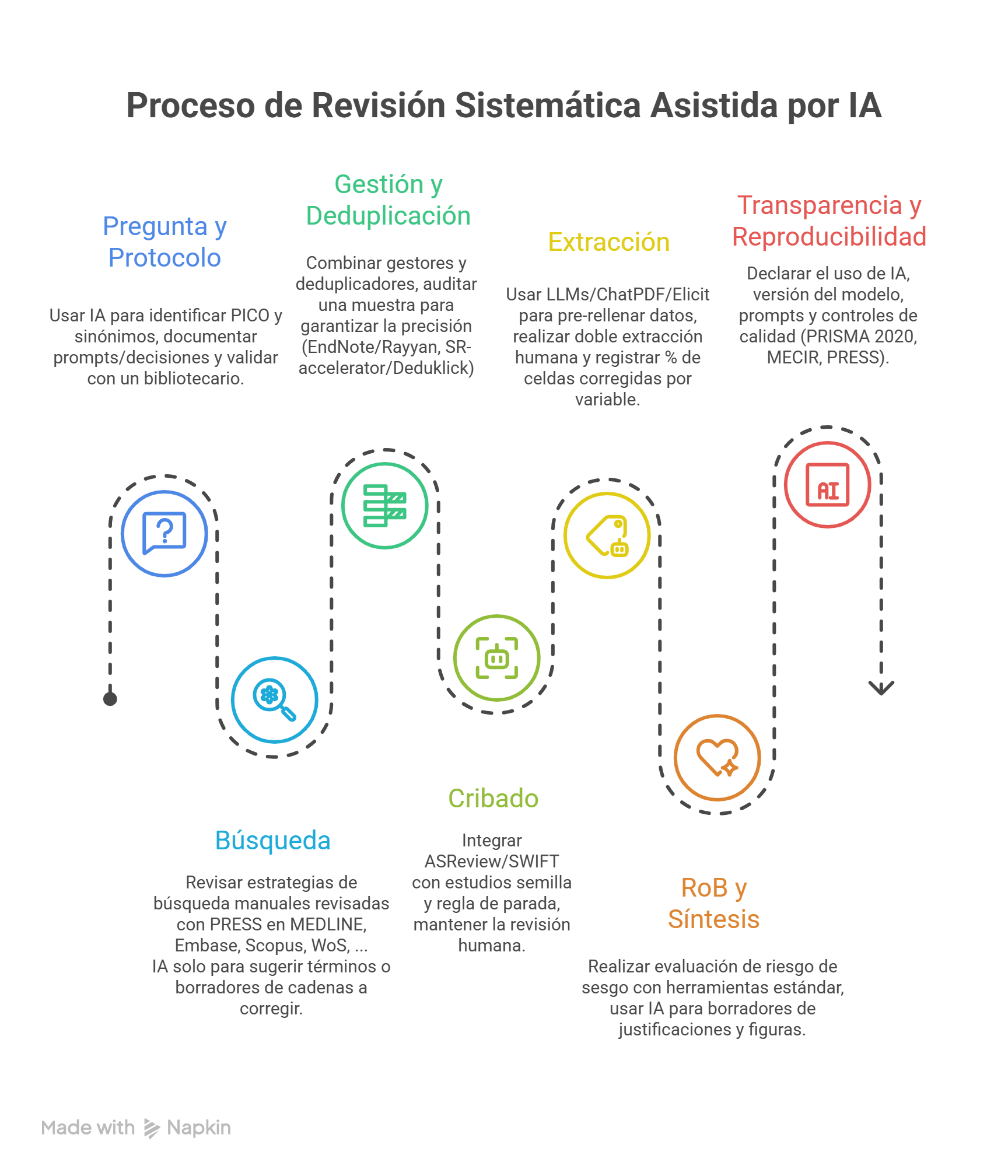
ASReview y SWIFT ActiveScreener alcanzaron recall altos en títulos/resúmenes (96,48% y 97,89%, respectivamente) y redujeron el number needed to read (NNR). En texto completo, Covidence y SWIFT obtuvieron recall 100% con precisión cercana al 50%, útil para priorizar sin suprimir la revisión humana. - Su uso en la primera fase del cribado frente al título/Abstract es prometedor pudiendo reducir la carga de trabajo significativamente, especialmente para el segundo revisor.
- Su uso en la fase de escreening frente al texto completo es limitado y todos los artículos deben cribarse para garantizar que no se pierda nada, a pesar de la precisión de la IA
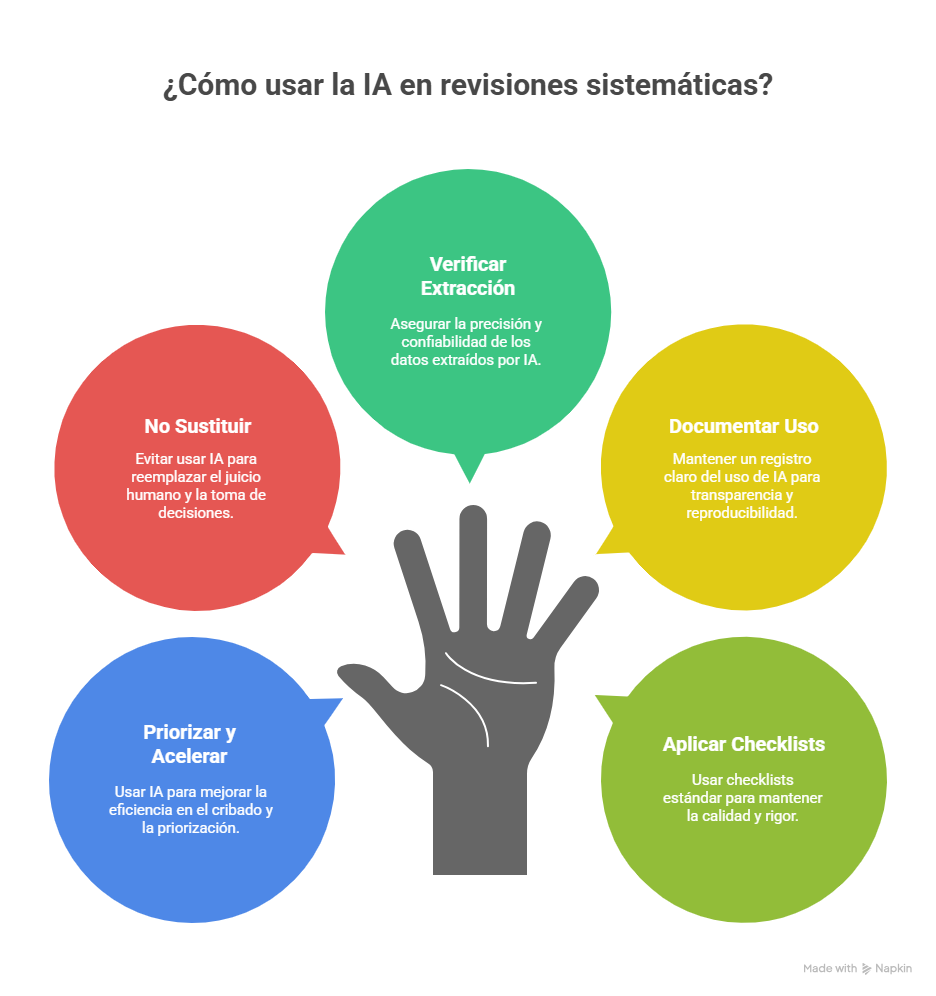
- La implicación general es que la IA en esta fase debe verse como una herramienta complementaria y de apoyo, y no como un sustituto completo del juicio y la experiencia humana
2) Extracción de datos (modo asistido)
- LLMs y asistentes tipo ChatGPT/Elicit/SciSpace pueden pre-rellenar tablas (autor, año, muestra, intervención…), pero la concordancia varía del 0% al 100% según el campo, y entre herramientas la fiabilidad puede ser baja-moderada; exige verificación por dos extractores humanos.
- La extracción de datos es una de las fases del proceso de RS más frecuentemente abordadas por estudios sobre LLMs (Modelos de Lenguaje Grande). La IA puede identificar y extraer información clave, como el diseño del estudio, los resultados, o el tema principal de un artículo, lo que potencialmente minimiza el error humano y reduce el esfuerzo manual3. Dado que la extracción de datos, junto con el cribado, es una de las partes que más tiempo consume en una RS, la capacidad de herramientas como ChatGPT y CoPilot para acelerar esta fase es considerada un beneficio importante. Sin embargo, pesar de los resultados prometedores, la IA aún no está lista para reemplazar la extracción manual y presenta importantes fallas de fiabilidad.
3) Apoyo metodológico y redacción
- Buen rendimiento para ideación de la pregunta, PICO, sinónimos y borradores de cadenas booleanas (que un especialista debe validar). En redacción, los LLMs ayudan a esqueletos de métodos/discusión y a preparar síntesis narrativas con control experto.
¿Dónde no conviene delegar (aún)?
A) Búsqueda bibliográfica “end-to-end”: rol de apoyo y supervisión humana
El debate en torno al uso de la Inteligencia Artificial (IA) en la fase de Búsqueda en las Revisiones Sistemáticas se centra en su prometedor potencial para agilizar tareas específicas, contrarrestado por una baja fiabilidad y sensibilidad al intentar reemplazar la metodología de búsqueda tradicional, lo que exige una constante supervisión humana.
- Baja Sensibilidad (Recall). Los buscadores IA (p. ej., Consensus, Elicit, SciSpace) mostraron recall muy bajo frente a estrategias manuales multibase: mejor caso ~18% y, en varios escenarios, 0–5%, en parte por cubrir Semantic Scholar y no bases con licencia/tras muro de pago. No sustituyen a MEDLINE/Embase/Scopus/WoS.
- Alucinaciones y falta de fiabilidad en las referencias.
- Inconsistencia en la Generación de Queries. Incluso cuando se limitan a la tarea de generar queries booleanas para bases de datos (un rol de asistencia), los resultados son impredecibles. Los LLMs no pueden recomendarse para la creación de estrategias de búsqueda complejas.
- La IA puede utilizarse para identificar términos clave para el desarrollo de la estrategia y para tareas generales de alcance.
Es crucial que un bibliotecario experto con conocimientos en metodología de revisión valide la estrategia generada por la IA y la edite manualmente, ya que las estrategias generadas por ChatBots podría comprometer los resultados. Se requieren habilidades de prompt engineering para optimizar el rendimiento de la IA en tareas de recuperación de información.
B) Riesgo de sesgo (RoB): esta etapa requiere juicio humano
El debate en torno al Rendimiento de las herramientas de Inteligencia Artificial (IA), como ChatGPT y RobotReviewer, en la etapa de Evaluación de Calidad o Riesgo de Sesgo (RoB) de las Revisiones Sistemáticas (RS), se centra en su pobre fiabilidad inter-evaluador (poor inter-rater reliability) y sus limitaciones metodológicas, lo que las hace actualmente inadecuadas para reemplazar la evaluación humana.
C) Extracción desde tablas/figuras complejas
Los LLMs fallan más cuando los datos están en tablas/figuras o mal estructurados; se necesita lectura experta y herramientas específicas de tablas.
Flujo recomendado: IA-asistida, humano en el bucle
Riesgos (y cómo mitigarlos)
- Alucinaciones y referencias falsas → Verificar DOI/PMID y cotejar con texto original.
- Cobertura parcial (sin licencias/“paywalls”) → Integrar bases tradicionales y accesos institucionales.
- Reproducibilidad inestable (prompts/temperatura) → Guardar prompts, fijar parámetros, usar corpus cerrado (RAG) cuando sea posible.
Recuerda:
Bibliografía
- Kowalczyk P. Can AI Review the Scientific Literaure? Nature. 2024;635:276-8, doi: 10.1038/d41586-024-03676-9.
- Lieberum J-L., Töws M., Metzendorf M-I., Heilmeyer F., Siemens W., Haverkamp C., et al. Large language models for conducting systematic reviews: on the rise, but not yet ready for use – a scoping review. 2024, doi: 10.1101/2024.12.19.24319326.
- Moens M., Nagels G., Wake N., Goudman L. Artificial intelligence as team member versus manual screening to conduct systematic reviews in medical sciences. iScience. 2025;28(10), doi: 10.1016/j.isci.2025.113559.
- Schmidt L., Cree I., Campbell F., WCT EVI MAP group Digital Tools to Support the Systematic Review Process: An Introduction. Evaluation Clinical Practice. 2025;31(3):e70100, doi: 10.1111/jep.70100.
