La inteligencia artificial está irrumpiendo con fuerza en la síntesis de evidencia. Un estudio reciente de la Agencia Canadiense de Medicamentos (CDA-AMC) ofrece datos interesantes que conviene conocer (Featherstone R, Walter M, MacDougall D, Morenz E, Bailey S, Butcher R, et al. Artificial Intelligence Search Tools for Evidence Synthesis: Comparative Analysis and Implementation Recommendations. Cochrane Evidence Synthesis and Methods. 2025;3(5):e70045, doi: 10.1002/cesm.70045.).
Este artículo tuvo como objetivo evaluar el potencial de herramientas de búsqueda basadas en inteligencia artificial (Lens.org, SpiderCite y Microsoft Copilot) para apoyar la síntesis de evidencia vs. métodos de búsqueda tradicionales y establecer recomendaciones de implementación bajo un enfoque “fit for purpose”, es decir, utilizar cada herramienta solo para tareas específicas donde aporten valor. Se evaluaron siete proyectos completados en la agencia, aplicando búsquedas de referencia (método tradicional) frente a búsquedas con cada herramienta de IA. Se midieron sensibilidad/recall, número necesario a leer (NNR), tiempo de búsqueda y cribado, y contribuciones únicas de cada herramienta. Además, se recogió experiencias de los especialistas en información sobre usabilidad, limitaciones y sorpresas en el uso de los tres sistemas.

Resultados
| Método / Herramienta | Sensibilidad promedio | Diferencias entre proyectos simples y complejos | NNR (número necesario a leer) | Tiempo de búsqueda | Observaciones principales |
| Métodos tradicionales | 0.98 – 1 (casi perfecta) | Consistentemente alta en todos los proyectos | Más bajo que IA | 2.88 h en promedio | Estándar de referencia, máxima fiabilidad |
| Lens.org | 0.676 | Simples: 0.816 Complejos: 0.6 | Más alto que el estándar (98 vs 83) | Mayor tiempo (2.25 h, más que Copilot o SpiderCite) | Mejor de las IA, pero menos eficiente; útil en búsquedas simples y de autores |
| SpiderCite | 0.23 – 0.26 | Similar en simples y complejos | Variable (Cited by mejor que Citing) | ~1.25 h | Muy baja sensibilidad, pero puede aportar referencias únicas en temas complejos; solo útil como complemento |
| Copilot | 0.24 (muy variable: 0–0.91 según proyecto) | Simples: 0.41 Complejos: 0.15 | Muy variable (mejor en simples, muy alto en complejos) | Más rápido (0.96 h promedio) | Dependiente de la calidad de los prompts; no sustituye estrategias, útil para sugerir palabras clave |
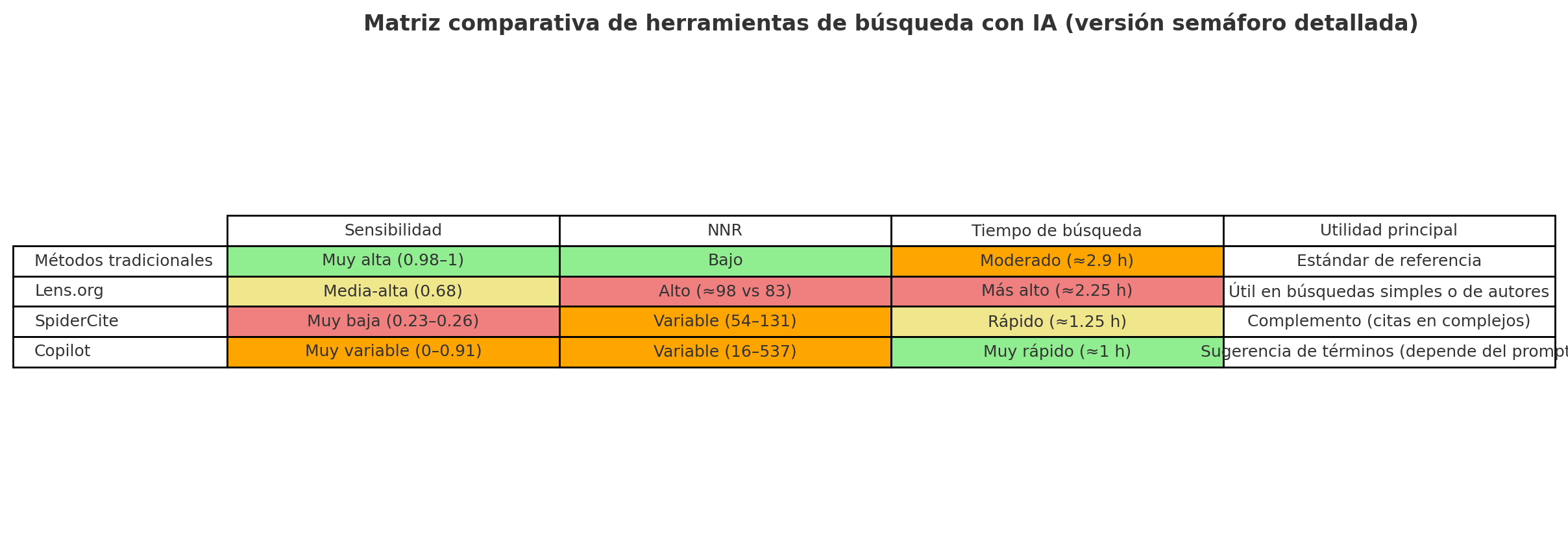
Sensibilidad = proporción de estudios relevantes efectivamente recuperados.
NNR = número necesario a leer; cuanto menor, mejor eficiencia de cribado.
Verde = mejor desempeño relativo. Amarillo = intermedio / aceptable. Rojo = débil. Naranja = muy variable según proyecto.
Discusión
- Las herramientas de IA mostraron rendimiento variable e inconsistente, lo que implica que no pueden reemplazar las búsquedas profesionales estándar en revisiones sistemáticas.
- Pueden generar falsa confianza en usuarios sin experiencia. Se requiere conocimiento experto en construcción de estrategias y en validación de resultados para corregir limitaciones.
- Limitaciones del estudio: solo se evaluaron 7 proyectos y 3 herramientas, sin analizar combinaciones entre ellas
Recomendaciones de implementación
La CDA-AMC propuso un uso limitado y estratégico:
- Lens.org: útil para revisiones con preguntas acotadas y técnicas (como dispositivos con una función o población bien definida) o para identificar rápidamente autores vinculados a un tema o indicación clínica cuando los métodos estándar no alcanzan.
- SpiderCite: complemento para búsquedas de citas en proyectos complejos, siempre que se disponga de artículos semilla.
- Copilot (u otros LLMs): apoyo en la generación de palabras clave y términos de búsqueda, pero no para estrategias completas
Conclusión
Las tres herramientas evaluadas (Lens.org, SpiderCite, Copilot) no son adecuadas para reemplazar estrategias de búsqueda complejas en revisiones sistemáticas, debido a variabilidad en sensibilidad y precisión. Sin embargo, tienen potencial como apoyos puntuales en tareas específicas: generación de términos, búsquedas simples o de citas, y exploración preliminar. El estudio subraya la necesidad de mantener el papel central del bibliotecario/experto en información en la validación de cualquier resultado generado con IA, y de continuar monitorizando nuevas herramientas dada la rápida evolución tecnológica.
Reflexiones para quienes trabajamos en bibliotecas médicas
- Las herramientas de IA pueden ahorrar tiempo en fases preliminares, generar ideas de términos de búsqueda, identificar autores, pero no deben utilizarse como única estrategia para revisiones sistemáticas si se espera exhaustividad.
- Es clave entender los límites: sensibilidad menor, posible sesgo en lo que captura IA, variabilidad según prompt o según lo cerrado o amplio que sea el tema.
- Siempre debe haber validación humana experta, verificación de resultados únicos que aparezcan en IA, comparación con lo recuperado por métodos tradicionales.
